Hi, DevOps fans. Welcome to series of articles devotes to AWS Fargate, autoscaling and terraform. I assume that you have read 4 parts at how to deploy web application at AWS Fargate using terraform and, as a result, you are aware of all terrafrom code related with that.
At that tutorial I will show you how to deploy step based autoscaling policies for CPU/memory utilization. For that purpose we will use terraform module. As always we will start from physical file structure:
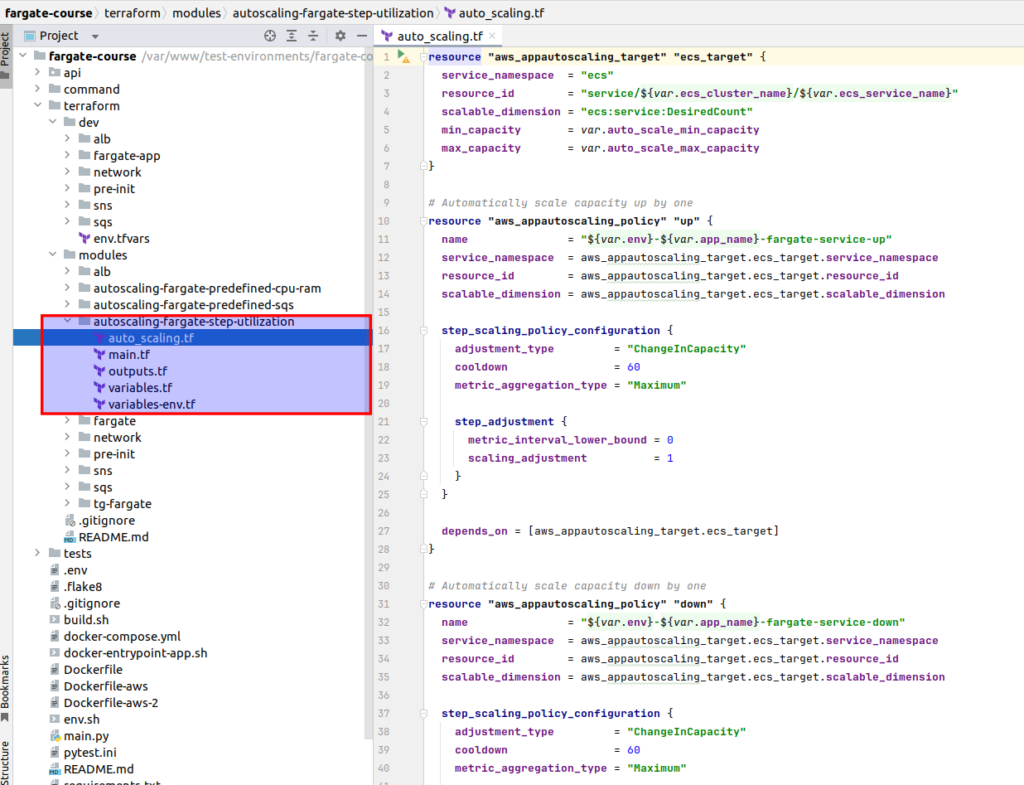
Here is the code for auto_scaling.tf file:
# auto_scaling.tf
resource "aws_appautoscaling_target" "ecs_target" {
service_namespace = "ecs"
resource_id = "service/${var.ecs_cluster_name}/${var.ecs_service_name}"
scalable_dimension = "ecs:service:DesiredCount"
min_capacity = var.auto_scale_min_capacity
max_capacity = var.auto_scale_max_capacity
}
# Automatically scale capacity up by one
resource "aws_appautoscaling_policy" "up" {
name = "${var.env}-${var.app_name}-fargate-service-up"
service_namespace = aws_appautoscaling_target.ecs_target.service_namespace
resource_id = aws_appautoscaling_target.ecs_target.resource_id
scalable_dimension = aws_appautoscaling_target.ecs_target.scalable_dimension
step_scaling_policy_configuration {
adjustment_type = "ChangeInCapacity"
cooldown = 60
metric_aggregation_type = "Maximum"
step_adjustment {
metric_interval_lower_bound = 0
scaling_adjustment = 1
}
}
depends_on = [aws_appautoscaling_target.ecs_target]
}
# Automatically scale capacity down by one
resource "aws_appautoscaling_policy" "down" {
name = "${var.env}-${var.app_name}-fargate-service-down"
service_namespace = aws_appautoscaling_target.ecs_target.service_namespace
resource_id = aws_appautoscaling_target.ecs_target.resource_id
scalable_dimension = aws_appautoscaling_target.ecs_target.scalable_dimension
step_scaling_policy_configuration {
adjustment_type = "ChangeInCapacity"
cooldown = 60
metric_aggregation_type = "Maximum"
step_adjustment {
metric_interval_upper_bound = 0
scaling_adjustment = -1
}
}
depends_on = [aws_appautoscaling_target.ecs_target]
}
# CloudWatch alarm that triggers the autoscaling up policy
resource "aws_cloudwatch_metric_alarm" "alarm_high" {
alarm_name = "${var.env}-${var.app_name}-${var.autoscaling_metric}-high"
comparison_operator = "GreaterThanOrEqualToThreshold"
evaluation_periods = "2"
metric_name = var.autoscaling_metric
namespace = "AWS/ECS"
period = "60"
statistic = "Average"
threshold = var.alarm_high_threshold
dimensions = {
ClusterName = var.ecs_cluster_name
ServiceName = var.ecs_service_name
}
alarm_actions = [aws_appautoscaling_policy.up.arn]
}
# CloudWatch alarm that triggers the autoscaling down policy
resource "aws_cloudwatch_metric_alarm" "alarm_low" {
alarm_name = "${var.env}-${var.app_name}-${var.autoscaling_metric}-low"
comparison_operator = "LessThanOrEqualToThreshold"
evaluation_periods = "2"
metric_name = var.autoscaling_metric
namespace = "AWS/ECS"
period = "60"
statistic = "Average"
threshold = var.alarm_low_threshold
dimensions = {
ClusterName = var.ecs_cluster_name
ServiceName = var.ecs_service_name
}
alarm_actions = [aws_appautoscaling_policy.down.arn]
}At the top we register an autoscaling target – it is completely the same as what we had at tracking policy, so there is nothing to discuss here. What you have indeed to concentrate your attention at – it is the aws_appautoscaling_policy parts. We are not setting policy type – as default value is step policy, though we can also set it explicitly. What we have to set up properly – it is step_scaling_policy_configuration:
- adjustment_type = “ChangeInCapacity” – Defines how capacity is adjusted when scaling is triggered. “ChangeInCapacity” means the number of instances will change by a fixed number.
- cooldown = 60 – Specifies a cooldown period of 60 seconds before another scaling action can take place. This prevents excessive scaling actions (flapping) and allows the system to stabilize before further changes.
- metric_aggregation_type = “Maximum” – Determines how the metric data is aggregated across instances. “Maximum” means the highest recorded metric value is considered for scaling decisions. Other options include “Minimum” (lowest value) and “Average” (mean value across instances).
- metric_interval_upper_bound = 0 – Sets the upper boundary for this step adjustment. “0” means this rule applies when the metric value is less than or equal to 0. If not defined, it applies to all values below the next highest step.
- scaling_adjustment = -1 – Specifies how the system should adjust capacity when this rule is triggered. -1 means remove one instance from the Auto Scaling Group when the metric falls within the defined range.
It is rather hard to understand initially how step_adjustment indeed works. That is why I decided to explain it in details. Here is the visualization that would be helpful:
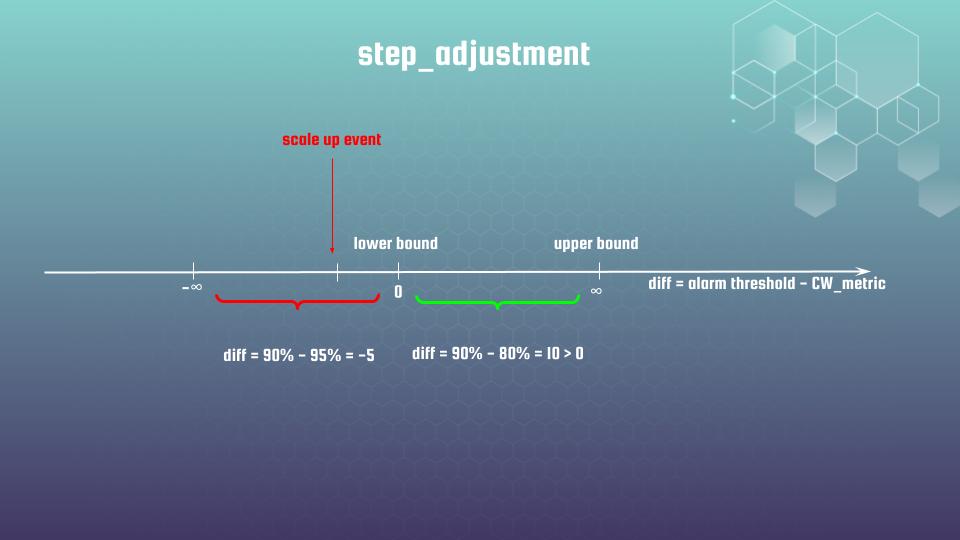
Lets investigate the resource “aws_appautoscaling_policy” “up” code block at first. We set metric_interval_lower_bound=0. The value for the metric_interval_lower_bound means the lower bound for the difference between the alarm threshold and the CloudWatch metric. When we do not set metric_interval_upper_bound AWS will treat this bound as infinity. Let’s assume that our metric is CPU utilization, and our acceptable CPU threshold value is 90%. In case high overloading CPU is going up to 95% – in that case difference between set up by us threshold will be 90% – 95% = -5%, which is below lower bound value, which also means that AWS Fargate would be scaled up.
That is what resource “aws_cloudwatch_metric_alarm” “alarm_high” exactly do – it fires scale up event when chosen by our metric would be greater to some concrete threshold. Meanwhile step adjustment policy “decides” whether the difference between actual and desired CPU utilization value is enough to apply scaling. In case lower bound is broken – new container is added. And visa versa, if CPU utilization is less that 90%m then “diff” would be positive, metric is placed between lower and upper bound – so no auto-scaling happens.
Resource “aws_appautoscaling_policy” “down” has mirrored logic, which also better to understand by using some visualization:
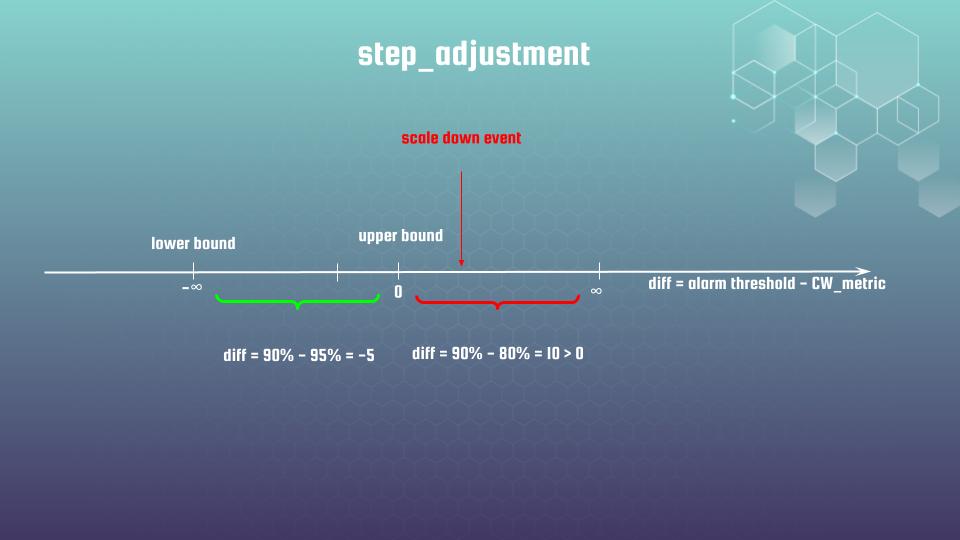
In that case we are setting metric_interval_upper_bound = 0, while lower bound is absent – it means minus infinity is used by AWS as default. Let me provide you module usage example now:
module "auto_scaling_fargate_step" {
source = "../../modules/autoscaling-fargate-step-utilization"
account_id = var.account_id
env = var.env
project = var.project
region = var.region
auto_scale_min_capacity = 1
auto_scale_max_capacity = 3
alarm_high_threshold = 70
alarm_low_threshold = 20
autoscaling_metric = "CPUUtilization"
ecs_cluster_name = module.fargate.ecs_cluster_name
ecs_service_name = module.fargate.ecs_service_name
app_name = module.fargate.app_name
}In that exactly case autoscaling_metric is set to the CPUUtilization. In case it would be higher then 70% within 1 min, then “up” autoscaling event would be fired, and number of containers would be increased, if max Fargate capacity, of course, allows that. When CPU utilization would be less then 20% within 1 min – “down” autoscaling event will decrease number of containers by 1. That is how step autoscaling policy adjusts number of containers to be running AWS Fargate cluster dependently at overloading. You may also have multiple steps with different up/down bounds thresholds, the same as you can use not only built in AWS CloudWatch alarms, but also custom one.
Generally speaking, step scaling allows you to implement almost whatever you want. You may define several different alarms, with a very granular step policy, adjusting the number of you containers in such a way, to satisfy almost any application requirements. You also have full freedom here at choosing alarm period time and evaluation period quantity, against which we want to measure chosen by us metric. You are limited only by your imagination, though remember, the more simply system – the more easier to support it.
I recommend to start from tracking autoscaling policy type at first, which is quite simple in realization, and only then, if it does not satisfy your requirement for some reasons, go further with step based option, which a little bit tricky for understanding.
Let me provide rest of the files from autoscaling terraform module (small notice – outputs.tf in that case is empty):
# main.tf
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = ">=5.32.1"
}
}
required_version = ">=0.14.5"
}# variables.tf
variable "ecs_cluster_name" {
type = string
}
variable "ecs_service_name" {
type = string
}
variable "app_name" {
type = string
}
variable "auto_scale_min_capacity" {
type = number
}
variable "auto_scale_max_capacity" {
type = number
}
variable "alarm_high_threshold" {
type = number
}
variable "alarm_low_threshold" {
type = number
}
variable "autoscaling_metric" {
type = string
validation {
condition = contains(["CPUUtilization", "MemoryUtilization"], var.autoscaling_metric)
error_message = "Valid values for var: autoscaling_metric are: CPUUtilization, MemoryUtilization."
}
}# variables_env.tf
variable "account_id" {
type = string
description = "AWS Account ID"
}
variable "env" {
type = string
description = "Environment name"
}
variable "project" {
type = string
description = "Project name"
}
variable "region" {
type = string
description = "AWS Region"
}
Thank you for the attention.
P.S. If you want to pass all material at once in fast and convenient way, with detailed explanations, then welcome to my course: “AWS Fargate DevOps: Autoscaling with Terraform at practice”, here you may find coupon with discount.