During the last two weeks, something weird started happening on one of the RDS instances I’m responsible for. Sudden, sharp peaks in active connections appeared — dozens of new ones almost instantly, then slowly disappearing. Within 5–10 minutes, the application would hang and become unresponsive.
This wasn’t just a minor blip; it was a full-blown mystery.
Phase 1: The Code Witch Hunt
The first peaks appeared almost immediately after one release, so the natural thought was: “Okay, the problem is probably somewhere here.” It looked way too suspicious to be a coincidence. So the developers and I started there.
Our first assumption was the classic one: new release → new problem.
We went through the changes, checking every possible query and service. We rolled back one commit. Then another. Then half of the release. Finally, we reverted everything.
And for a moment, it seemed that the problem was fixed. No spikes. The metrics were calm. Everyone felt satisfied.
Until several days later — the peaks returned. Same pattern, same intensity, completely random timing.

At that point, everyone was confused. We had no clue what it was. And as it often happens in life — problems don’t come alone. There was indeed a small DB connection loop in the code, but it wasn’t the main issue that triggered everything. The real villain was still hiding.
Phase 2: The Mystery of the Vanishing CPU Credits
With the code cleared of being the prime suspect, I turned my attention to RDS. The instance is a db.t3.large — one of those burstable instances that earn and spend CPU credits depending on utilization.
I’ve used T-class instances for years. They’re perfect for workloads with mixed idle and burst periods. But I never really dug into how those credits behave during weird traffic patterns. Now I had to. Digging into the CloudWatch metrics, I saw something strange:
- CPUUtilization hovered around 20–40% — well below the ~60% baseline for a t3.large.
- But CPUCreditBalance stayed flat at zero.

So I was below baseline… but still not earning credits? That made no sense.
Then I learned about the fine print. In Unlimited mode (the default for RDS T3/T4g), when you’ve previously gone above baseline, the instance borrows future credits to maintain performance. Later, when you go below baseline, it must first repay that “CPU debt” before it can earn new credits to its balance.
That debt is shown in a different metric: CPUSurplusCreditBalance — and indeed, it was positive and barely decreasing.
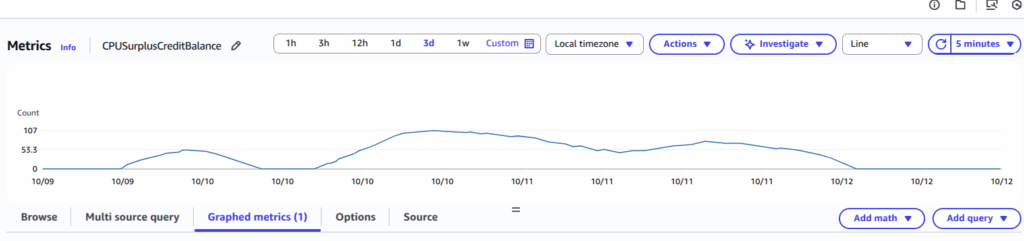
So technically, the instance was earning credits, but every new one was instantly used to pay off the surplus balance. That explained why the balance graph looked flat.
Mystery half-solved — but the connection spikes were still a puzzle.
Phase 3: The Idle DB That Wasn’t Idle
The next clue came from the DatabaseConnections metric. Yes, the peaks were obvious, but there was another interesting observation. Even at night, when traffic was minimal, the baseline number of active connections was higher than ever before.
I checked the app logs — nothing. No cron storms, no stuck workers, no queue bursts.
Then I went back through the change history and found something: a DevOps update I had made—scaling EC2 instances and adjusting the PHP-FPM pool configuration. Could that possibly be related?
I opened the pool config and saw these changes:
Before:
pm = ondemand
pm.max_children = 4After:
pm = dynamic
pm.max_children = 88
pm.start_servers = 16
pm.min_spare_servers = 12
pm.max_spare_servers = 32Right. It was me who changed it from ondemand to dynamic during scaling. The reason was to handle high traffic spikes from AI bots that our app couldn’t handle properly. As a temporary solution, I doubled the resources and switched PHP-FPM to dynamic mode to pre-create workers and handle spikes faster.
At that time, it felt like a harmless and reasonable optimization. But that was the smoking gun.
Phase 4: The PHP-FPM Twist and the Connection Storm
If you’re not deep into FPM internals, here’s how this simple change created our nightmare. Each FPM worker process has its own lifecycle — and often, its own persistent database connection.
- In ondemand mode, FPM spawns workers only when a request arrives. After a timeout (pm.process_idle_timeout), idle workers are killed. → When there’s no traffic, there are very few workers and almost no DB connections.
- In dynamic mode, FPM keeps a minimum pool of workers alive (pm.min_spare_servers) even when there’s no traffic. When traffic hits, it aggressively spawns new children to maintain that spare pool. → Those workers stay running — and so do their open DB connections, creating a higher idle load. → During a traffic surge, its attempt to maintain a large spare pool (max_spare_servers = 32) caused it to spawn dozens of workers at once.
So, while trying to solve one problem (slow response to spikes), I had created a much worse one. The dynamic configuration was too aggressive. When a burst of traffic hit, it launched a tidal wave of workers, each opening a new database connection. The database choked, the application hung, and the CPU credits burned away trying to manage the chaos.
That explained everything.
Phase 5: Confirmation and Fix
To verify, I changed the configuration back to ondemand. Within hours, the metrics transformed:
- The baseline connection count dropped steadily during idle hours.
- DB connection high peaks finally disappeared.
CPU RDS credit usage, gradually, returning to normal values.
It was one of those “of course” moments — obvious only after you see it.
What I Learned (the Hard Way)
When debugging RDS issues, it’s tempting to start with the code. But sometimes the “bug” hides in the infrastructure, not in PHP or SQL.
- Not All CPU Credits Are Created Equal. If your CPUCreditBalance isn’t increasing despite low CPU, check for a positive CPUSurplusCreditBalance. You might be paying off old debts. Also, remember that surplus credits can have cost implications if you consistently use them.
- FPM Mode Matters More Than You Think. The choice between ondemand and dynamic is a critical trade-off between resource usage and performance.
- ondemand: Fewer idle workers, fewer idle DB connections, faster credit recovery. Great for low-traffic or predictable environments.
- dynamic: Pre-spawned workers, constant DB load even when idle. Can offer better performance for traffic spikes, but requires careful tuning.
Be Careful with dynamic Mode Configuration. Too many spare servers can create a wave of new DB connections — enough to hang your application. On a burstable instance, that’s a recipe for draining your CPU credits.
My Action Plan: Recovery and Prevention
The immediate fix is done, but now it’s about building a more resilient system.
1. Wait until CPU credits are fully recovered. The instance needs to pay off its surplus debt first.
2. Try a less aggressive dynamic configuration. I’ll re-introduce dynamic mode but with much more conservative values, reducing the max spare servers to prevent connection storms.
pm.max_spare_servers = 16 // Down from 32
pm.start_servers = 12 // Down from 16
pm.min_spare_servers = 8 // Down from 12
3. Experiment with RDS Proxy. This is the big one. RDS Proxy is a managed connection pooler from AWS that sits between your application and the database. In theory it may completely prevent this issue by taking the flood of connection requests from PHP-FPM and funneling them through its own smaller, stable pool of connections to the database. It’s the perfect shock absorber. But it is too early to make any summaries – theory is not practice 🙂
Lesson learned: sometimes the difference between a calm RDS and a credit-burning nightmare is just one line in an FPM config.
Small recommendation in the end – if you still do not have CW alarms at DatabaseConnections and CPUCreditBalance – it is a good time to add it 🙂