Hi, DevOps fans
It is often required to perform some cyclic tasks at the database with cleaning different garbage, e.g removing old records at database. There are several options how can we do it AWS cloud:
- Running ECS scheduled tasks
- Running scheduled lambda functions
- Running own scripts using dockerized application and cron at EC2
Though all of those methods definitely generate additional costs. There is also another option that is rarely used, but worth, as for me, of our attention. It is adding scheduled events at the database by itself. In the current current article I would like to show you how we can add such an scheduled event at AWS RDS using terraform. Current approach will often allow to reduce AWS costs in comparison to solutions mentioned above.
In most cases AWS RDS instances are deployed at private networks, which is definitely a good idea from security reasons. But it also creates an obstacle – as it is not so easy to get to DB from the terraform side. As result, there is no option to simply run some SQL statements, e.g using some local executor and DB credentials. But still, there is rather good option how it can be done.
I will use for that purpose lambda function, that would be deployed at the same VPC as an RDS instance. Current lambda would be created and invoked as a terraform module instantly after RDS terraform module will create according instance. For the current learning example we will assume that:
- our RDS instance would be using MariaDB engine
- we are having some “test” db, where we would like to clean some “logs” table regularly – e..g we want to remove all records older then 60 days
Ok, lets skip to realization.
Here is how physical files structure looks like:
Lets start from data.tf:
data "aws_iam_policy_document" "lambda" {
version = "2012-10-17"
statement {
sid = "LambdaAssumeRole"
effect = "Allow"
actions = ["sts:AssumeRole"]
principals {
identifiers = ["lambda.amazonaws.com"]
type = "Service"
}
}
}
data "archive_file" "db_query_executor_handler_zip_file" {
output_path = "${path.module}/lambda_zip/db-query-executor.zip"
source_dir = "${path.module}/handlers"
excludes = ["__init__.py", "*.pyc"]
type = "zip"
}
data "template_file" "lambda_ssm_access" {
template = file("${path.module}/policies/lambdaSsmAccess.json")
vars = {
account_id = var.account_id
project = var.project
region = var.region
env = var.env
}
}Here we define lambda assume policy, archive file resource to zip our lambda function, and finally there is an policy, that allows lambda to take DB credentials from SSM. Here is how it looks:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"ssm:GetParameters",
"ssm:GetParameter",
"ssm:GetParametersByPath",
"secretsmanager:GetSecretValue"
],
"Resource": [
"arn:aws:ssm:${region}:${account_id}:parameter/${project}/${env}/rds/*"
]
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": [
"ssm:DescribeParameters",
"kms:Decrypt"
],
"Resource": "*"
}
]
}Of, course, you will probably need to adjust Resources section according to your demands. At layers folder python mysql library is placed. And here is layers.tf file’s content:
resource "aws_lambda_layer_version" "db_query_executor_pymysql" {
filename = "${path.module}/layers/db-query-executor-pymysql.zip"
layer_name = "db-query-executor-pymysql"
source_code_hash = filebase64sha256("${path.module}/layers/db-query-executor-pymysql.zip")
skip_destroy = true
compatible_runtimes = ["python3.10"]
}Now we need to define different boring IAM stuff – iam.tf:
resource "aws_iam_role" "lambda_db_query_executor" {
name = "${local.name_prefix}-db-query-executor-${var.operation_name}"
assume_role_policy = data.aws_iam_policy_document.lambda.json
tags = merge(local.common_tags, {
Name = format("%s-%s", local.name_prefix, "db-query-executor")
})
lifecycle {
create_before_destroy = true
}
}
resource "aws_iam_role_policy_attachment" "db_query_executor_attach_lambda_basic_execution" {
role = aws_iam_role.lambda_db_query_executor.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"
}
resource "aws_iam_role_policy_attachment" "db_query_executor_attach_eni_management_access" {
role = aws_iam_role.lambda_db_query_executor.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaENIManagementAccess"
}
resource "aws_iam_policy" "lambda_ssm_access" {
name = "${local.name_prefix}-lambdaSsmAccess-${var.operation_name}"
description = "Lambda ssm access policy"
policy = data.template_file.lambda_ssm_access.rendered
}
resource "aws_iam_role_policy_attachment" "db_query_executor_attach_lambda_ssm_access" {
role = aws_iam_role.lambda_db_query_executor.name
policy_arn = aws_iam_policy.lambda_ssm_access.arn
}
Several words here. So, at code above, lambda role is created at first, then I am adding AWS predefined basic execution lambda role – that’s classical part. What you can be non familiar with – it is AWSLambdaENIManagementAccess – it required in order our lambda function could register itself at VPC, where DB is located. Finally, we are adding ssm policy from template, that was defined at data.tf section.
Now, here is the heart of our module – lambda resource definition at terraform side + lambda handler code:
resource "aws_lambda_function" "db_query_executor" {
function_name = "${local.name_prefix}-db-query-executor-${var.operation_name}"
filename = data.archive_file.db_query_executor_handler_zip_file.output_path
source_code_hash = data.archive_file.db_query_executor_handler_zip_file.output_base64sha256
role = aws_iam_role.lambda_db_query_executor.arn
handler = "db-query-executor.lambda_handler"
runtime = "python3.8"
layers = [aws_lambda_layer_version.db_query_executor_pymysql.arn]
environment {
variables = {
SSM_DB_ENDPOINT_KEY = var.ssm_db_endpoint_key
SSM_DB_USERNAME_KEY = var.ssm_db_username_key
SSM_DB_PASSWORD_KEY = var.ssm_db_password_key
DB_NAME = var.db_name
SQL_QUERY = var.sql_query
}
}
vpc_config {
subnet_ids = var.subnets[*].id
security_group_ids = [var.sg.id]
}
timeout = 300
memory_size = 256
reserved_concurrent_executions = 1
tags = local.common_tags
lifecycle {
create_before_destroy = true
}
}
resource "aws_lambda_invocation" "example" {
function_name = aws_lambda_function.db_query_executor.function_name
input = jsonencode({})
}import os
import boto3
import pymysql
import logging
import time
LOGGER_FORMAT = '%(asctime)s,%(msecs)d %(levelname)-8s [%(filename)s:%(lineno)d] %(message)s'
logger = logging.getLogger()
logger.setLevel(logging.INFO)
ssm = boto3.client('ssm')
def lambda_handler(event, context):
try:
db_username = get_ssm_parameter(os.environ['SSM_DB_USERNAME_KEY'])
db_password = get_ssm_parameter(os.environ['SSM_DB_PASSWORD_KEY'])
db_endpoint = get_ssm_parameter(os.environ['SSM_DB_ENDPOINT_KEY'])
db_host, db_port = db_endpoint.split(":")
except Exception as e:
msg = f"Something went wrong at extracting secretes from SSM: {e}"
logger.error(msg, exc_info=True)
raise RuntimeError(msg)
try:
conn = pymysql.connect(
host=db_host,
port=int(db_port),
user=db_username,
password=db_password,
db=os.environ['DB_NAME']
)
with conn.cursor() as cursor:
cursor.execute(os.environ['SQL_QUERY'])
conn.commit()
conn.close()
except Exception as e:
msg = f"Something went wrong at running SQL query: {e}"
logger.error(msg, exc_info=True)
raise RuntimeError(msg)
msg = f"SQL query executed successfully: {os.environ['SQL_QUERY']}"
logger.info(msg)
return {
'statusCode': 200,
'body': 'SQL query executed successfully'
}
def get_ssm_parameter(name):
try:
response = ssm.get_parameter(Name=name, WithDecryption=True)
return response['Parameter']['Value']
except Exception as e:
msg = f"Error extracting secrets from SSM: {str(e)}"
logger.error(msg, exc_info=True)
raise RuntimeError(msg)
The python code is rather easy to understand – we simply get credentials from SSM (according key names are passed as env vars), and then use current credentials to connect at DB instance to run upon it SQL statement (which is passed as var also). After lambda resource created, I am using aws_lambda_invocation to run it instantly – though you may want to change current behaviour with using some CloudWatch event 🙂 . What is can be obscure here, especially for terraform beginner – it is question of permissions. Please, pay attention at security groups part from terraform side. The main idea is represented at scheme below:
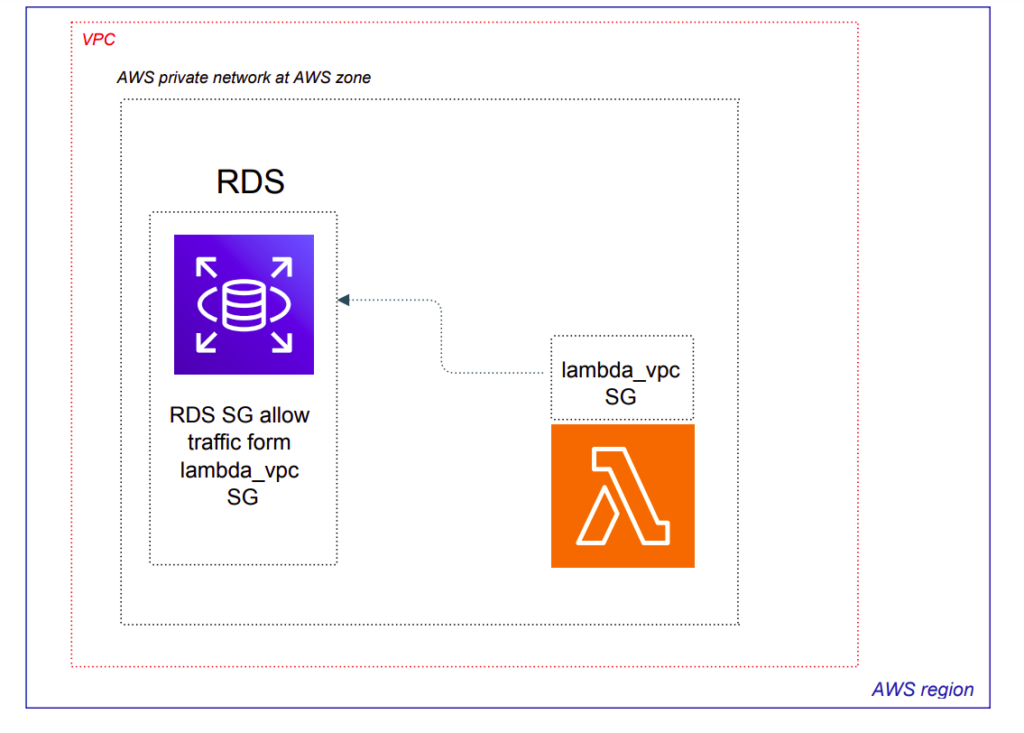
It is worth to create some lambda VPC security group and attach it to lambda function. Such SG can be implemented at your network terraform module (which is outside the scope of current article) and then passed at output of such a module to be used at lambda module implementation. Here is the example of realization for such a SG :
resource "aws_security_group" "lambda_vpc" {
description = "Lambda VPC"
name = "Lambda VPC"
vpc_id = aws_vpc.main.id
lifecycle {
create_before_destroy = true
}
tags = merge(local.common_tags, {
Name = "${local.name_prefix}-lambda-vpc"
})
}
### EGRESS
resource "aws_security_group_rule" "lambda_vpc_egress" {
description = "Lambda VPC Egress"
type = "egress"
from_port = 0
to_port = 65535
protocol = "all"
cidr_blocks = ["0.0.0.0/0"] # tfsec:ignore:AWS007
security_group_id = aws_security_group.lambda_vpc.id
}
### ICMP
resource "aws_security_group_rule" "lambda_vpc_icmp" {
description = "Lambda VPC ICMP"
type = "ingress"
from_port = -1
to_port = -1
protocol = "icmp"
cidr_blocks = ["0.0.0.0/0"] # tfsec:ignore:AWS006
security_group_id = aws_security_group.lambda_vpc.id
}
### INGRESS - EMPTY
While having lambda VPC security group, you also need to allow traffic from it at your RDS Security group. Here is some example how can you do it:
### SG resource definition for DB and ingress/egress rules
### ..... code is omitted for readability
###
### FROM Lambda VPC
resource "aws_security_group_rule" "db_lambda_vpc" {
description = "From Lambda VPC"
type = "ingress"
from_port = 3306
to_port = 3306
protocol = "tcp"
security_group_id = aws_security_group.db.id
source_security_group_id = aws_security_group.lambda_vpc.id
}There is one more essential notice. In current realization you will also need to have SSM VPC endpoint to be configured – otherwise lambda, while being at private network, will not be able to get SSM parameters. In case you are already using SSM VPC endpoint, which I assume in most case true, then there is nothing to disturb about. But if not – please remember about one more thing – VPC endpoint will generate ~7$ per month.
But you can avoid that cost also – instead of getting SSM parameters, you may pass DB credentials directly to lambda envs as rds terraform modules outputs. The cons of that solution – DB credentials would be visible at at lambda by itself, which is not the best practice, though it quite possible that current solution can be acceptable for you.
Ok, let’s finish coding. Below is the content for the rest of files from lambda module:
#variables.tf
variable "subnets" {
type = set(object({
arn = string
assign_ipv6_address_on_creation = bool
availability_zone = string
availability_zone_id = string
cidr_block = string
id = string
ipv6_cidr_block = string
ipv6_cidr_block_association_id = string
map_public_ip_on_launch = bool
outpost_arn = string
owner_id = string
tags = map(string)
timeouts = map(string)
vpc_id = string
}))
}
variable "sg" {
description = "Lambda security group"
type = object({
arn = string
description = string
egress = set(object({
cidr_blocks = list(string)
description = string
from_port = number
ipv6_cidr_blocks = list(string)
prefix_list_ids = list(string)
protocol = string
security_groups = set(string)
self = bool
to_port = number
}))
id = string
ingress = set(object({
cidr_blocks = list(string)
description = string
from_port = number
ipv6_cidr_blocks = list(string)
prefix_list_ids = list(string)
protocol = string
security_groups = set(string)
self = bool
to_port = number
}))
name = string
name_prefix = string
owner_id = string
revoke_rules_on_delete = bool
tags = map(string)
timeouts = map(string)
vpc_id = string
})
}
variable "db_name" {
type = string
}
variable "ssm_db_password_key" {
type = string
}
variable "ssm_db_username_key" {
type = string
}
variable "ssm_db_endpoint_key" {
type = string
}
variable "sql_query" {
type = string
}
variable "operation_name" {
type = string
}
variable "db_identifier" {
type = string
}# variables-env.tf
variable "account_id" {
type = string
description = "AWS Account ID"
}
variable "env" {
type = string
description = "Environment name"
}
variable "project" {
type = string
description = "Project name"
}
variable "region" {
type = string
description = "AWS Region"
}
#main.tf
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.21"
}
}
required_version = "~> 1.6"
}And finally here is how implementation “mockup” can looks like:
terraform {
backend "s3" {
bucket = "some-bucket"
dynamodb_table = "some-table"
encrypt = true
key = "some-key"
region = "your-aws-region"
}
}
data "terraform_remote_state" "network" {
backend = "s3"
config = {
bucket = "some-bucket"
key = "some-key"
region = var.region
}
}
provider "aws" {
allowed_account_ids = [var.account_id]
region = var.region
}
module "rds" {
source = "../../modules/rds"
### your rds module realization
}
module "db-query-executor" {
source = "../../modules/db-query-executor"
account_id = var.account_id
env = var.env
project = var.project
region = var.region
sg = data.terraform_remote_state.network.outputs.sg_lambda_vpc
subnets = data.terraform_remote_state.network.outputs.subnets_private
db_name = "test"
ssm_db_password_key = "your key name"
ssm_db_username_key = "your key name"
ssm_db_endpoint_key = "your key name"
sql_query = <<-EOF
CREATE EVENT IF NOT EXISTS AutoDeleteOldNotifications
ON SCHEDULE EVERY 5 MINUTE
STARTS CURRENT_TIMESTAMP
DO
DELETE FROM logs
WHERE created_at < NOW() - INTERVAL 60 DAY LIMIT 1000;
EOF
operation_name = "delete-old-logs"
db_identifier = "your db identifier"
depends_on = [module.rds]
}
Hope you have found current article to be interesting. If you are interested at AWS cloud, the same as I am, then welcome to my Udemy courses related with it:
- DevSecOps: How to secure web application with AWS WAF and CloudWatch
- AWS devops: Elasticsearch at AWS using terraform and ansible
Best regards