Hi, and welcome to the 5th article devoted to the theme: “How to work with ElasticSearch, Python and Flask”. Previous article (Part 4: Python and Flask ElasticSearch – builder pattern and DTO search criteria object) is located here. At that article we are going to investigate the heart of our microservice – model data layer. As a reminder I am providing our architecture scheme
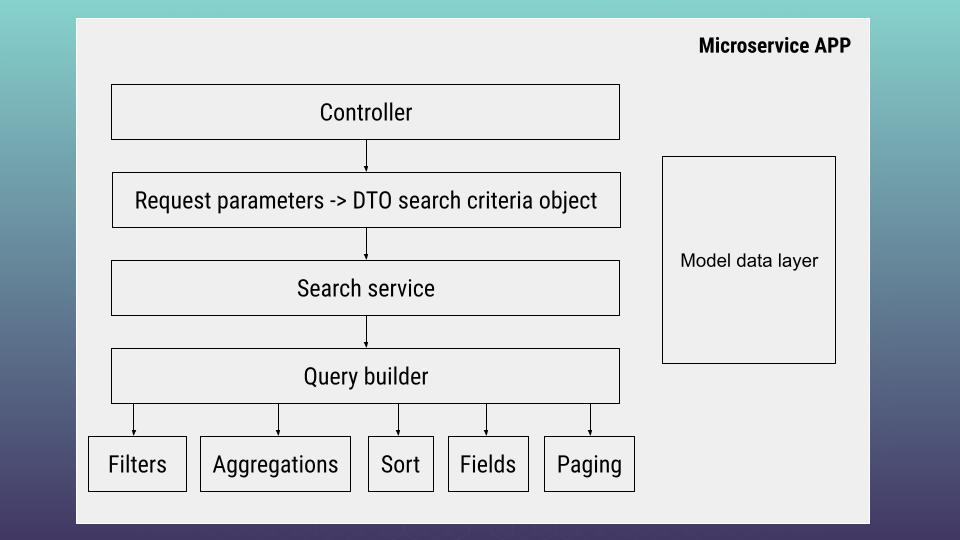
As you can guess our search has to be integrated with the ElasticSearch engine. To realize such integration it is better to look for ready solutions e.g python package that will allow us to speed up our work. Here I am going to use elasticsearch-dsl-py. Everything starts from data. So, at first we have to describe our data structure using objects. Let’s go to the documents folder and open hotels.py file
# src/elasticsearch/documents/hotels.py
from elasticsearch_dsl import Document, Join
HOTELS_INDEX = "hotels_index"
class Hotels(Document):
class Index:
name = HOTELS_INDEX
settings = {
"number_of_shards": 1,
"number_of_replicas": 0,
}
hotel_booking = Join(relations={"hotel": "booking"})
@classmethod
def _matches(cls, hit):
# Hotels is an abstract class, make sure
# it never gets used for deserialization
return False
def save(self, **kwargs):
return super(Hotels, self).save(**kwargs)Please, pay attention here at 3 things:
- indexes section – here we define our ElasticSearch index and additional essential index settings: number_of_replicas, shards. I will describe what that parameters at further lectures.
- join relationship – as you remember every hotel has list of bookings. Hotel and bookings are connected as parent – child relation
- hotels – is an abstract
Below we define Hotel and Booking models that are extended from Hotels abstract. Here is the code for according classes:
import src.elasticsearch.documents as documents
from elasticsearch_dsl import Float, Date
class Booking(documents.Hotels):
price = Float()
date = Date()
@classmethod
def _matches(cls, hit):
""" Use Booking class for child documents with child name 'booking' """
return (
isinstance(hit["_source"]["hotel_booking"], dict)
and hit["_source"]["hotel_booking"].get("name") == "booking"
)
@classmethod
def search(cls, **kwargs):
return cls._index.search(**kwargs).exclude("term", hotel_booking="hotel")
@property
def hotel(self):
# cache hotel in self.meta
# any attributes set on self would be interpretted as fields
if "hotel" not in self.meta:
self.meta.hotel = documents.Hotel.get(
id=self.hotel_booking.parent, index=self.meta.index
)
return self.meta.hotel
def save(self, **kwargs):
# set routing to parents id automatically
self.meta.routing = self.hotel_booking.parent
return super(Booking, self).save(**kwargs)Booking class is rather simple – it has only 2 properties (date, price) , hotel method (that used for resolving parent-child relation), search method (that used for searching child booking documents) and save method (that resolves routing elasticsearch issues). Most of that things are simply taken from official pyhton elasticsearch dsl package documentation. Now let’s investigate Hotel model class:
from elasticsearch_dsl import Text, Integer, Nested, GeoPoint, Float, Boolean
from src.elasticsearch.documents.comment import Comment
from src.elasticsearch.documents.hotels import Hotels
from src.elasticsearch.documents.booking import Booking
class Hotel(Hotels):
hotel_id = Integer()
name = Text()
city_name_en = Text()
location = GeoPoint()
age = Integer()
free_places_at_now = Boolean()
stars = Integer()
rating = Float()
comments = Nested(Comment)
def add_comment(self, hotel_id, content, stars, created_at):
c = Comment(hotel_id=hotel_id, content=content, stars=stars, created=created_at)
self.comments.append(c)
return c
@classmethod
def _matches(cls, hit):
""" Use Booking class for parent documents """
return hit["_source"]["hotel_booking"] == "hotel"
@classmethod
def search(cls, **kwargs):
return cls._index.search(**kwargs).filter("term", hotel_booking="hotel")
def add_booking(self, price, date, commit=True):
booking = Booking(
# required make sure the answer is stored in the same shard
_routing=self.meta.id,
# since we don't have explicit index, ensure same index as self
_index=self.meta.index,
# set up the parent/child mapping
hotel_booking={"name": "booking", "parent": self.meta.id},
# pass in the field values
price=price,
date=date
)
if commit:
booking.save()
return booking
def search_bookings(self):
# search only our index
s = Booking.search()
# filter for booking belonging to us
s = s.filter("parent_id", type="hotel", id=self.meta.id)
# add routing to only go to specific shard
s = s.params(routing=self.meta.id)
return s
def get_bookings(self):
"""
Get bookings either from inner_hits already present or by searching
elasticsearch.
"""
if "inner_hits" in self.meta and "booking" in self.meta.inner_hits:
return self.meta.inner_hits.booking.hits
return list(self.search_bookings())
def save(self, **kwargs):
self.hotel_booking = "hotel"
return super(Hotel, self).save(**kwargs)
Hotel class is a little bit more complicated, it has more properties, different methods for operating with child documents. In addition it process operation of adding comments which are represented as nested objects
from elasticsearch_dsl import InnerDoc, Text, Integer, Date
class Comment(InnerDoc):
hotel_id = Integer()
content = Text()
stars = Integer()
created_at = Date()
Using object oriented approach we are representing data that would be used by ElasticSearch via according classes. Please, pay attention at class properties. Every property has according dsl package class type. Python dsl package use that classes to create proper index mapping. Here I am not discovering why exactly such architecture was chosen (parent child relationship, nested objects) or why exactly such type of mapping used for every field. If you are interested in that, please refer to my course at udemy, where I am discovering mapping and architecture aspects in details
At the next lecture (Part 6: Python Flask ElasticSearch – indexer command) we will go further with creating our search microservice. Together, we will create python command which would be used for creating mapping for our index using our model classes. That command will also provide indexing of some initial test data to ElasticSearch index. If you would like to pass all material more fast, then I propose you to view my on-line course at udemy where you will also find full project skeleton. Below is the link to the course. As the reader of that blog you are also getting possibility to use coupon for the best possible low price. Otherwise, please wait at next articles. Thank you for you attention.