Hi, devops fans.. At 2d part we finished with cluster configuration, vpc, network, security group settings. At current article we will concentrate at storage, CloudWatch alarms and variables. So, where and how better to preserve our data? Such a simple question appears to be rather complicated issue in case OpenSearch. I would like to start here from official ElasticSearch recommendations. Please, pay attention to that part: “When selecting disk please be aware of the following order of preference”:
- EFS – Avoid as the sacrifices made to offer durability, shared storage, and grow/shrink come at performance cost, such file systems have been known to cause corruption of indices, and due to Elasticsearch being distributed and having built-in replication, the benefits that EFS offers are not needed.
- EBS – Works well if running a small cluster (1-2 nodes) and cannot tolerate the loss all storage backing a node easily or if running indices with no replicas. If EBS is used, then leverage provisioned IOPS to ensure performance.
- Instance Store – When running clusters of larger size and with replicas the ephemeral nature of Instance Store is ideal since Elasticsearch can tolerate the loss of shards. With Instance Store one gets the performance benefit of having disk physically attached to the host running the instance and also the cost benefit of avoiding paying extra for EBS.
Ok, so seems instance storage by itself is preferable. But here is a small pitfall waiting for us. Now let’s visit terrafrom documentation. It looks like from the 1st glance that ebs_options are optional. And here is an interesting note: “may be required based on chosen instance size”.
Let’s click at link from screen above and look at the “instance storage” column. And as you see we are limited here a lot. In most cases we simply are forced to use EBS storage despite it not being a preferable option from ElasticSearch recommendations, especially when we are speaking about big production clusters.
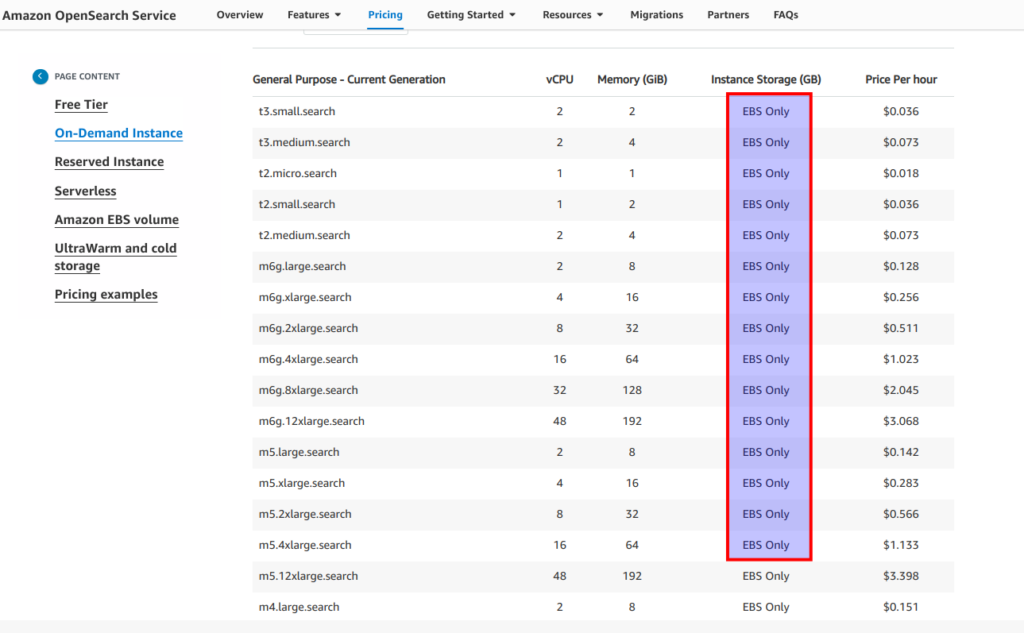
Generally AWS offer for us even more storage options – here is the nice article which I recommend to read. So in fact AWs propose us 3 different types for our data. In short it is hot storage – for fast operations (we can consider it to be as a internal storage or EBS (which we already know is not the most fast option)), then we have ultrawarm storage – that is proposed to be used for some less frequently used data (under the hood s3 will be used a storage) and so called “cold storage”. What it means in practice – all depends on your data retention, query latency, and budget requirements. You are able to get what you want, but as for me we have here rather big limitations for choosing instance storage that makes opensearch, from cost effectivenes perspective, to be a completely unsuitable solution in some cases. Though, from my personal commercial experience, it appears that EBS storage works rather well. I did not notice any bigger difference EBS vs internal storage, but who knows – maybe in some cases it can have greater meaning. For learning purposes, I will stay with EBS, as I am going to use t3.small.search instances to not overload students and myself with excessive costs. Here is terrafrom part of es.tf related to the EBS options:
......
ebs_options {
ebs_enabled = true
volume_size = var.volume_size
volume_type = "gp2"
}
......Now lets go forward with CloudWatch alarms. I decide to write a separate article devoted to OpenSearch monitoring – I will place a link to it at main article related to AWS and OpenSearch, alternatively you may subscribe to my newsletter. Below is terraform skeleton where you can start from – feel free to use it. Using terraform, I defined the most essential OpenSearch cluster parameters that are worth to be monitored in my opinion.
# terraform/modules/opensearch/alarms.tf
resource "aws_cloudwatch_metric_alarm" "elastisearch_cpu_usage" {
alarm_name = "ct-${var.env}-elastisearch-cpu-usage"
namespace = "AWS/ES"
metric_name = "CPUUtilization"
comparison_operator = "GreaterThanOrEqualToThreshold"
statistic = "Average"
threshold = "85"
period = "60"
evaluation_periods = "5"
# you my send notification using SNS - example below
#alarm_actions = [aws_sns_topic.YourTopicName.arn]
dimensions = {
DomainName = var.domain_name
ClientId = var.account_id
}
}
resource "aws_cloudwatch_metric_alarm" "elastisearch_free_space" {
alarm_name = "ct-${var.env}-elastisearch-free-space"
namespace = "AWS/ES"
metric_name = "FreeStorageSpace"
comparison_operator = "LessThanThreshold"
statistic = "Minimum"
threshold = "5000"
period = "60"
evaluation_periods = "5"
dimensions = {
DomainName = var.domain_name
ClientId = var.account_id
}
}
resource "aws_cloudwatch_metric_alarm" "elastisearch_cluster_status" {
alarm_name = "ct-${var.env}-elastisearch-cluster-status"
namespace = "AWS/ES"
metric_name = "ClusterStatus.green"
comparison_operator = "LessThanThreshold"
statistic = "Average"
threshold = "1"
period = "60"
evaluation_periods = "5"
dimensions = {
DomainName = var.domain_name
ClientId = var.account_id
}
}
resource "aws_cloudwatch_metric_alarm" "elastisearch_cluster_nodes" {
alarm_name = "ct-${var.env}-elastisearch-cluster-nodes"
namespace = "AWS/ES"
metric_name = "Nodes"
comparison_operator = "LessThanThreshold"
statistic = "Average"
threshold = "2"
period = "60"
evaluation_periods = "5"
treat_missing_data = "notBreaching"
dimensions = {
DomainName = var.domain_name
ClientId = var.account_id
}
}
resource "aws_cloudwatch_metric_alarm" "elastisearch_cluster_memory" {
alarm_name = "ct-${var.env}-elastisearch-cluster-memory"
namespace = "AWS/ES"
metric_name = "JVMMemoryPressure"
comparison_operator = "GreaterThanOrEqualToThreshold"
threshold = "88"
evaluation_periods = "3"
statistic = "Maximum"
period = "300"
dimensions = {
DomainName = var.domain_name
ClientId = var.account_id
}
}Let’s have a fast glance at other typical files. Here is locals.tf – as always we define custom tags here.
# terraform/modules/opensearch/locals.tf
locals {
name_prefix = format("%s-%s", var.project, var.env)
common_tags = {
Env = var.env
ManagedBy = "terraform"
Project = var.project
}
}Env variables – that is as always things related to AWS account, env and project.
# terraform/modules/opensearch/variables-env.tf
variable "account_id" {
type = string
description = "AWS Account ID"
}
variable "env" {
type = string
description = "Environment name"
}
variable "project" {
type = string
description = "Project name"
}
variable "region" {
type = string
description = "AWS Region"
}And our main module variables. Please, pay attention to sg and subents – that is a format we should preserve as we are going to pass current values from our s3 remote state.
# terraform/modules/opensearch/variables.tf
variable "subnets" {
type = set(object({
arn = string
assign_ipv6_address_on_creation = bool
availability_zone = string
availability_zone_id = string
cidr_block = string
id = string
ipv6_cidr_block = string
ipv6_cidr_block_association_id = string
map_public_ip_on_launch = bool
outpost_arn = string
owner_id = string
tags = map(string)
timeouts = map(string)
vpc_id = string
}))
}
variable "sg" {
type = object({
arn = string
description = string
egress = set(object({
cidr_blocks = list(string)
description = string
from_port = number
ipv6_cidr_blocks = list(string)
prefix_list_ids = list(string)
protocol = string
security_groups = set(string)
self = bool
to_port = number
}))
id = string
ingress = set(object({
cidr_blocks = list(string)
description = string
from_port = number
ipv6_cidr_blocks = list(string)
prefix_list_ids = list(string)
protocol = string
security_groups = set(string)
self = bool
to_port = number
}))
name = string
name_prefix = string
owner_id = string
revoke_rules_on_delete = bool
tags = map(string)
timeouts = map(string)
vpc_id = string
})
}
variable "domain_name" {
type = string
}
variable "versionES" {
type = string
}
variable "instance_type" {
type = string
}
variable "instance_count" {
type = number
}
variable "az_count" {
type = number
}
variable "volume_size" {
type = number
}
variable "automated_snapshot_start_hour" {
type = string
}Just as a summary – I am also presenting the whole terrraform code for the es.tf file
# terraform/modules/opensearch/es.tf
resource "aws_iam_service_linked_role" "es" {
aws_service_name = "es.amazonaws.com"
}
resource "aws_opensearch_domain" "es" {
domain_name = var.domain_name
engine_version = var.versionES
encrypt_at_rest {
enabled = true
}
cluster_config {
instance_type = var.instance_type
instance_count = var.instance_count
zone_awareness_enabled = true
zone_awareness_config {
availability_zone_count = var.az_count
}
}
vpc_options {
subnet_ids = slice(var.subnets[*].id, 0, var.az_count)
security_group_ids = var.sg[*].id
}
ebs_options {
ebs_enabled = true
volume_size = var.volume_size
volume_type = "gp2"
}
snapshot_options {
automated_snapshot_start_hour = var.automated_snapshot_start_hour
}
log_publishing_options {
cloudwatch_log_group_arn = aws_cloudwatch_log_group.opensearch.arn
enabled = true
log_type = "ES_APPLICATION_LOGS"
}
log_publishing_options {
cloudwatch_log_group_arn = aws_cloudwatch_log_group.opensearch.arn
enabled = true
log_type = "SEARCH_SLOW_LOGS"
}
node_to_node_encryption {
enabled = true
}
advanced_options = {
"rest.action.multi.allow_explicit_index" = "true"
}
access_policies = <<CONFIG
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "es:*",
"Principal": "*",
"Effect": "Allow",
"Resource": "arn:aws:es:${var.region}:${var.account_id}:domain/${var.domain_name}/*"
}
]
}
CONFIG
advanced_security_options {
enabled = false
}
depends_on = [aws_iam_service_linked_role.es]
tags = {
Domain = var.domain_name
}
}And that’s it – we are ready to go forward with implementation. But let’s do it at another article, where we will deploy OpenSearch cluster at AWS using terraform module and use OpenSearch dashboard to index some test documents and run simple search query upon it. Please, check my blog regularly or simply subscribe to my newsletter. Alternatively, you may pass all material at once in convenient and fast way at my on-line course at udemy. Below is the link to the course. As the reader of that blog you are also getting possibility to use coupon for the best possible low price.