How cyber security fans. Welcome to the 3d part of articles related with AWS WAF managed rules. As you already remember from previous article, we already have deployed WAF with different managed rule groups. We also switched all of them at count mode to analyse if any of rules generate false positives at application traffic. For that purpose we already turn on WAF log’s mechanism and now we are going to analyse this data. To do that – we will use Athena. If you have never heard about that AWS tool – here is the link to documentation, and here is short explanation
Amazon Athena is an interactive query service that makes it easy to analyze data directly in Amazon Simple Storage Service (Amazon S3) using standard SQL.
Athena requires several configuration steps. I prepared separate article about how to provide according configuration, which includes video tutorial lecture from my course “DevSecOps: How to secure Web App with AWS WAF and CloudWatch” You may find it here.
So, I assume that:
- you attached WAF for your application and switched all AWS WAF managed rules to count mode;
- one or two weeks have passed (or several days) and it is time to investigate WAF log’s data;
- you configured Athena for using WAF S3 logs.
Let me show you now how to analyse which requests had to be blocked by WAF AWS managed rules, but still were passed because of count mode. Here is the query, which will help us to get according data:
SELECT i, httprequest.clientip, httprequest.uri, httprequest.args
FROM waf_logs CROSS JOIN UNNEST(rulegrouplist) as r(i) where i.terminatingrule.action = 'BLOCK'
and to_iso8601(from_unixtime(timestamp / 1000)) >= '2024-02-11T15:00:31.000'As you understand – you need to replace date and time at your values :). I am not going to explain why that query built in such a way. If you are interested in details – please, refer to my course. At that moment I propose to concentrate in 2 columns: rulegrouplist and httprequest. Rulegrouplist will show us, which WAF rules were applied, and httprequest fields will show us against what it was applied for. Rulegrouplist is represented as a nested JSON structure. Let’s examine it in detail. I copied data from my course – one row and formatted it.
[
{
"rulegroupid=AWS#AWSManagedRulesAmazonIpReputationList",
"terminatingrule=null",
"nonterminatingmatchingrules="[
],
"excludedrules=null"
},
{
rulegroupid=AWS#AWSManagedRulesCommonRuleSet#Version_1.10,
"terminatingrule=null",
"nonterminatingmatchingrules="[
],
"excludedrules=null"
},
{
rulegroupid=AWS#AWSManagedRulesLinuxRuleSet#Version_2.2,
"terminatingrule="{
"ruleid=LFI_HEADER",
"action=BLOCK",
"rulematchdetails=null"
},
"nonterminatingmatchingrules="[
],
"excludedrules=null"
},
{
rulegroupid=AWS#AWSManagedRulesSQLiRuleSet#Version_1.1,
"terminatingrule=null",
"nonterminatingmatchingrules="[
],
"excludedrules=null"
}
]At every Rulegrouplist you will find every managed group, which is attached to WAF. In that case it is 4 groups and at every group section you may find info if any rules were matched. You can notice that AWSManagedRulesLinuxRuleSet was one match to the rule LFI_HEADER. Current action means that WAF would like to block that request, but it was not done as we set all rules, including LFI_HEADER, at count mode.
So, in such a way you may get information about every request which WAF would like to block, the same as which AWS managed WAF rules were applied in every concrete case. Now, by using logical analysis and httprequest values, you can check if all malicious requests, that WAF would like to block, are indeed true positives, or we have some false positives and, as result, some rules can’t be applied at block action and should stay in count mode.
Now imagine that you have a real production application with thousand visitors per day. That will generate a lot of traffic. Yes, only some small percent of it will land as potentially malicious requests that should be blocked – but it is still a lot of data for analyzing. How to deal with that challenge?
First of all I recommend creating an Excel document with the next structure:
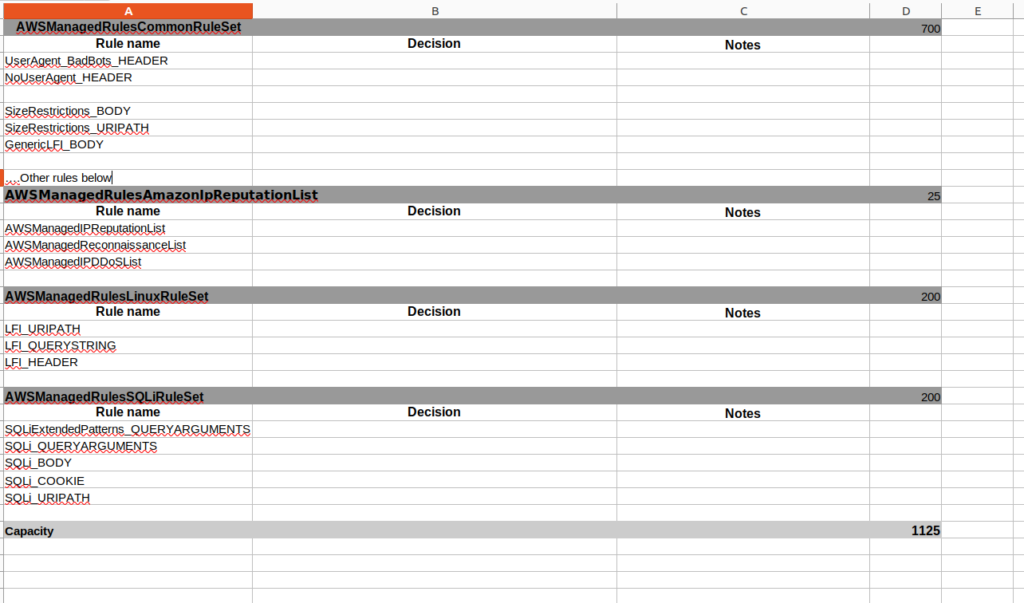
At the next step you may narrow the data set for analyzing by selecting only potentially malicious requests from concrete group or concrete rules. Here is the the example of query:
SELECT i, httprequest.clientip, httprequest.uri, httprequest.args
FROM waf_logs CROSS JOIN UNNEST(rulegrouplist) as r(i) where
i.terminatingrule.action = 'BLOCK'
and to_iso8601(from_unixtime(timestamp / 1000)) >= '2024-02-11T15:00:31.000'
and i.rulegroupid='AWS#AWSManagedRulesLinuxRuleSet#Version_2.2'
and (i.terminatingrule.ruleid = 'LFI_HEADER'
or i.terminatingrule.ruleid = 'LFI_URIPATH'
or i.terminatingrule.ruleid = 'LFI_QUERYSTRING')After that, download results in csv format and send it to your team for the verification of false positives. And now essential notice – the verification should be done with high quality, so please, delegate the current task only to the people who really know the application well from technical side. As we are lazy creations that are always looking for ways to make our life easier, you may ask: Is it possible to speed up the process? The answer is YES. Here are mine recommendations:
- Simply check if the current rule can not be excluded from simple logical considerations. For example – you may do not block requests if user agent is missing (there is such a rule at common rule set).
- Use test environment + tests:
- Deploy app at test env
- Turn on all groups and all rules you chose to add at block mode
- Run “browser automation” tests (e.g selenium)
- Exclude all rules from data analyse and false positives verification that caused test’s fails
- Add according rules at exclude list from terraform side
In such a way you may find in a fast way apparent false positives and reduce the amount of data for analyzing. After you will analyse your data and define all rules that generate false positives, it is time to make an excluded and blocked list at terrafom and apply according changes. And now my another essential recommendation. For small applications with low traffic – you may do it at once, but for bigger ones – do it gradually. By term “bigger” I mean applications with high traffic, where you have over 10000 visitors per day, or it can be applications with rather broad functionality, e.g hundreds of api points, urls and different path scenarios. You may ask – But WHY? The reasons are the next one:
- Mistakes at verification process
- Not enough data. If your verification is “big”, then it is quite possible that some rarely used functionalities or user’s behaviour scenarios exist.
I doubt that any tests are able to cover all cases at 100%. At least I did not meet such a case within my 18th year practice. Though who knows, maybe it happens :). In big web applications it is quite possible that some request structures can appear once a month or even once per several months. What if such rare requests were not included in the verification process and would be finally blocked by WAF? How to deal with that in a safe way? We for sure don’t want to block real customers that bring us money. Let me represent for you the algorithm that worked for me the best. But let’s do it at the next and final article: “AWS WAF managed rules configuration methodology and rules versions“.
If you are not ready to wait, or prefer to pass all material in a fast and more convenient way – then welcome to my course, were you can pass all material in a fast and convenient way. Here you can find coupon with discount, which I am updating regularly in the middle of every month.