Hi, devops fans. That is the second part of the article devoted to AWS OpenSearch service performance benchmark. The 1st one can be found here.
Let’s start with the OpenSearch Benchmark utility. You may find more details about how it works here. It is rather easy to install and use the OpenSearch utility, so I will not go into details on how to use it, but will concentrate on some results. There are several essential notices before we will analyse some numbers:
- In all cases OpenSearch cluster was deployed in a private network. To get access to the cluster I used ssh tunneling at a local PC, where all tests were run using percolator workload:
opensearch-benchmark execute-test --pipeline=benchmark-only --workload=percolator --target-host=https://localhost:9200 --test-mode- I was mostly interested in “Mean Throughput” and latency parameters. Below in the table you will find according values for different perlocators. I will not provide all of them here – only several. To make the table more readable I removed the prefix “percolator_with_content” from the prelocator name, e.g, percolator_with_content_google was replaced with google. Value 8.03 ops/s | 171 ms from first cell should be treated as next output from opensearch utility:
Mean Throughput | percolator_with_content_president_bush | 8.03 | ops/s |
100th percentile latency | percolator_with_content_president_bush | 171.953 | ms |Here is the table with results:
| Cluster/prelocator name | president _bush | saddam _hussein | hurricane _katrina | high lighting | |
| EC2 3 node cluster – docker memory limit 6Gb, jvm – 4GB, ec2 – t3.large (2 CPU, 8 GB) | 8.03 ops/s | 171 ms | 11.65 ops/s | 138 ms | 12.63 ops/s | 131 ms | 5.85 ops/s | 241 ms | 8.33 ops/s | 168 ms |
| EC2 3 node cluster – docker memory limit 14Gb, jvm – 12GB, ec2 – t3.xlarge (4 CPU, 16 GB) | 9.67 ops/s | 145 ms | 12.97 ops/s | 119 ms | 12.48 ops/s | 119 ms | 9.74 ops/s | 149 ms | 11.77 ops/s | 143 ms |
| aws opensearch – 3 nodes t3.medium.search (2 CPU, 4 GB) | 3.37 ops/s | 465 ms | 6.39.ops/s | 338 ms | 6.29 ops/s | 307 ms | 3.52 ops/s | 442 ms | 4.86 ops/s | 376 ms |
| aws opensearch – 3 nodes m6g.large.search (2 CPU, 8 GB) | 6.34 ops/s | 310 ms | 6.16 ops/s | 306 ms | 6.46 ops/s | 293 ms | 6.52 ops/s | 304 ms | 5.85 ops/s | 332 ms |
| aws opensearch – 3 nodes r6g.large.search (2 CPU, 16 GB) | 3.98 ops/s | 405 ms | 5.86 ops/s | 336 ms | 5.4 ops/s | 331 ms | 4.61 ops/s | 384 ms | 5.72 ops/s | 347 ms |
| aws opensearch – 3 nodes c6g.xlarge.search (4 CPU, 8 GB) | 2.76 ops/s | 515 ms | 5.79 ops/s | 319 ms | 5.86 ops/s | 323 | 4.65 ops/s | 371 ms | 4.99 ops/s | 360 ms |
Several conclusions can be made from current data:
- Own served cluster at EC2 instances looks much more better from performance side relatively to AWS OpenSearch service
- Cheaper general purpose instances (m6g.large.search) appeared to be better solution then more expensive memory (r6g.large.search) or CPU optimized (c6g.xlarge.search) types, which is rather strange and confusing
Now, time to speak about sending reports overload tests. First of all, I can definitely say that some positive changes appeared – I could not recreate the 429 error problem any more. All clusters could bear overloading of 10K SQS jobs. Here is how number of deleted messages looked like for different cluster configurations
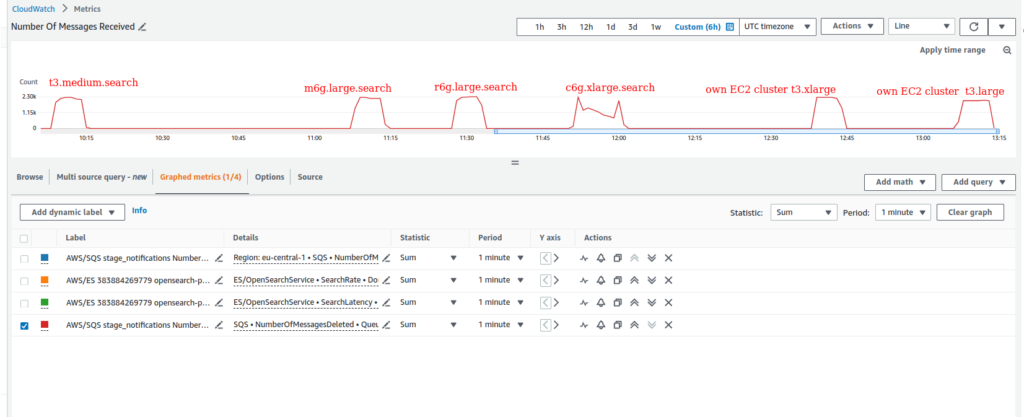
In all cases behavior was almost the same. Except computed optimized instance type (c6g.xlarge.search), where the situation looked a little bit more worse, but still acceptable.
It was also interesting to measure search rate and latency. In case own EC2 cluster based at t3.large (2 CPU, 8 GB) – I used average values from production cluster basing at Zabbix ElasticSearch monitoring data values:
- Search rate ~ 250 in peaks
- Average query latency – 60 ms – current Zabbix metric is not the same as SearchLatency for OpenSearch – but still it will allow ro make some rough comparison
Sorry, but I was too lazy to configure Zabbix monitoring on my own ec2 clusters. Though I had not – it would be clear from results below. In case OpenSearch I’ve got next results:
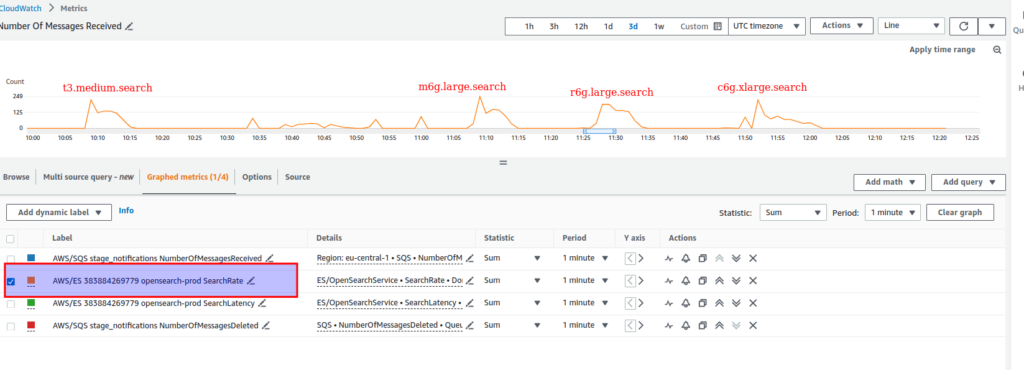
In general, the search rate (The total number of search requests per minute for all shards on a data node) was at ~125 for almost all OpenSearch cluster configurations, except a little bit worse value for c6g.xlarge.search.
Here is the search latency for t3.medium.search cluster – it appeared so high relatively to other options – > 300 ms, so I have to show it separately
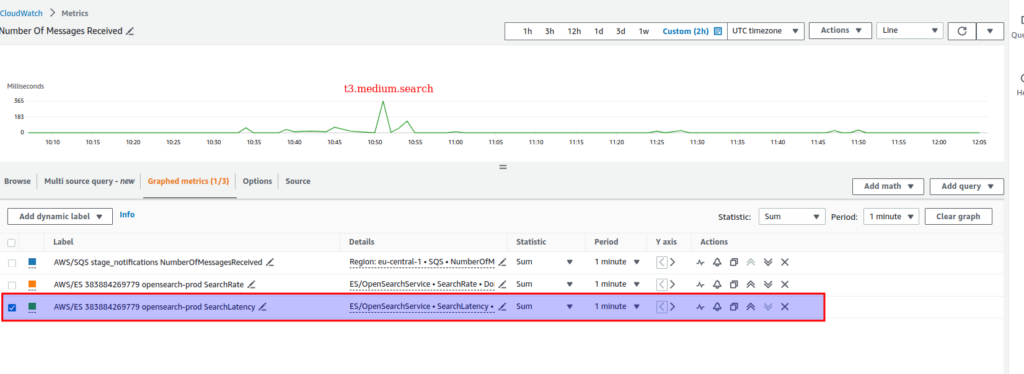
For other options results were the next:
- m6g.large.search – 3ms
- r6g.large.search – ~24ms
- c6g.xlarge.search – ~28 ms
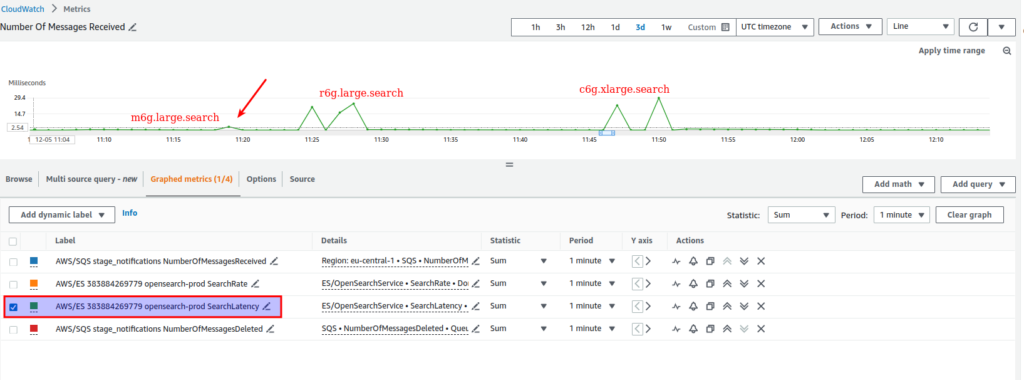
So, let’s make a summary:
- The own 3 node ec2 cluster built upon t3.large instances is able to process more requests than similar or even more powerful OpenSearch solutions. Though, suppose it is mostly related with network latency, which is much more lower in case app and Elasticsearch are located at the same server, then when we have to send request at separate service
- Despite it is rather hard to compare query latency Zabbix metric with OpenSearch SearchRate, I suppose we can admit here, that ec2 t3.large ElasticSearch cluster does not look some especially worst looking at it’s OpenSearch competitors
- Sending reports overload tests confirmed rather strange observation from OpenSearch benchmark utility tests – looking at search latency parameter, general purpose instances (m6g.large.search) appeared to be better solution then more expensive memory (r6g.large.search) or CPU optimized (c6g.xlarge.search). It is really hard to explain the current result, though I still have one supposition. The search queries used for generating reports are memory and CPU consuming at the same time. As a result, in my concrete case, it appears that general instances are dealing with such a type of requests better than optimized competitors – but it is only a supposition.
And, now the last, but very essential notice – the price. Please, have a look at aws calculator results for different options in case taking upfront 1 year reservation:
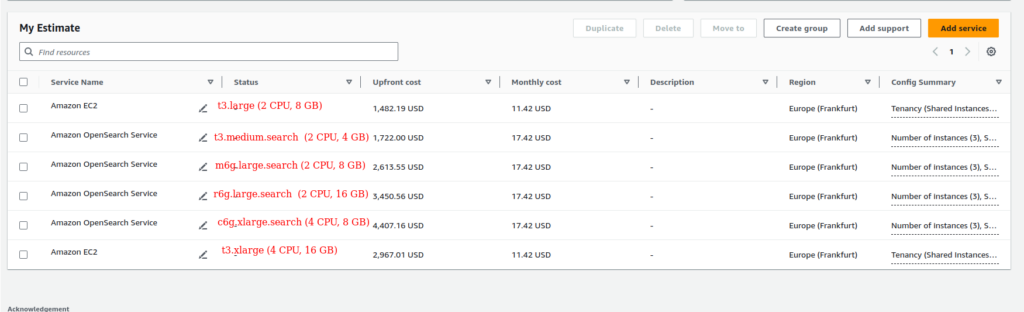
As for me, something is no yes here. Here are my considerations. While having EC2 t3.large own cluster I have to pay ~1500$ per year, moreover, I am able to run Search App at the same servers. While migrating to the OpenSearch alternative solution based at m6g.large.search I have to pay + 1200$ per year. In addition I will have to add the Fargate year cost, which would be at least 500$ more, and that is bypassing costs for data transfer.
But what do I really get for that? High availability – nope, I already have it. Better monitoring – I already have it at Zabbix. Backups – maybe, though in my case frequent backups are not so essential, and I still can use s3 Elasticsearch snapshot plugin. Autoscaling? Yes, that is probably the only that works better at AWS service. I can autoscale my cluster only vertically using ansible scripts, but AWS OpenSearch allows you to provide horizontal scaling using blue-green deployment, though there are a lot of limitations here. You can learn about it at my course AWS devops: Elasticsearch at AWS using terraform and ansible. But what if I don’t need that autoscaling, what am I getting in the final result?
Seems I am getting a worse solution from the performance side for higher cost. Nope, really, I like AWS and all they do, but some things are still far from good. Ok, wait, but how about the typical statement that you will hear often from AWS consultants: “Yes, you will pay more, but take into consideration operational cost reduction for support”.
Let’s try to calculate that operational cost:
- Linux packages upgrade at EC2 – once per quarter (suppose it is enough), 1 hour on every upgrade (which is more than optimistic) – we are getting 4 hours. In case we will delegate it to some outsource for 40-50$ per hour – it gives us < 200$.
What else? I don’t see any other expenditures that would be another one, then in case using OpenSearch, e.g reindexing, monitoring, cluster optimizations. And what if I have several more similar applications that also use Elasticsearch as backend data storage? And what if I need more memory – e.g 10 or 12 Gb, but not 16Gb – please, have a look at that price – 4000 $ per year, and it is without excessive hidden costs for storage and data transfer with upfront 1 year prepaid.
Generally speaking, when I am hearing the phrase: “Cloud will decrease your cost”, I am always smiling. NO, it will always be more expensive, the question is only what you will get for that money. Problem is that in the case of OpenSearch, I have to pay money for a “worse” solution (relative to my own EC2 based cluster), and that is what I really don’t like. While paying for something much more I expect to get a better product from all sides – performance, HA, usability, monitoring, scalability. Another question is the price by itself. There is no need to pay the Elasticsearch company for any licences, isn’t it? So, why is OpenSearch service still so expensive as AWS ElasticSearch service? We can only guess. If somebody from AWS “high” managers is reading the current article, please, reconsider your billing policy to AWS OpenSearch and make it technically better.
Thank you for you attention
P.S.
Below are the links to the courses, where you can find a lot of useful and, first of all, practical information about Elasticsearch and OpenSearch: