Hi, DevOps fans
Recently, 04.12.2023-05.12.2023. I have a pleasant occasion to perform AWS OpenSearch service performance benchmarks. The reason for that has a rather long story, but I will try to shorten it as much as possible. There is one application that uses Elasticsearch for performing different search operations. I will call it “Search App” below in text. Current application was migrated to AWS Cloud almost 2 years ago. To not complicate the situation, at 1st migration step it was decided to move Search App from 3 “on-premise” servers to the 3 EC2 instances preserving existing docker swarm architecture, with only some small adjustments. The simplified architecture scheme took a next view:
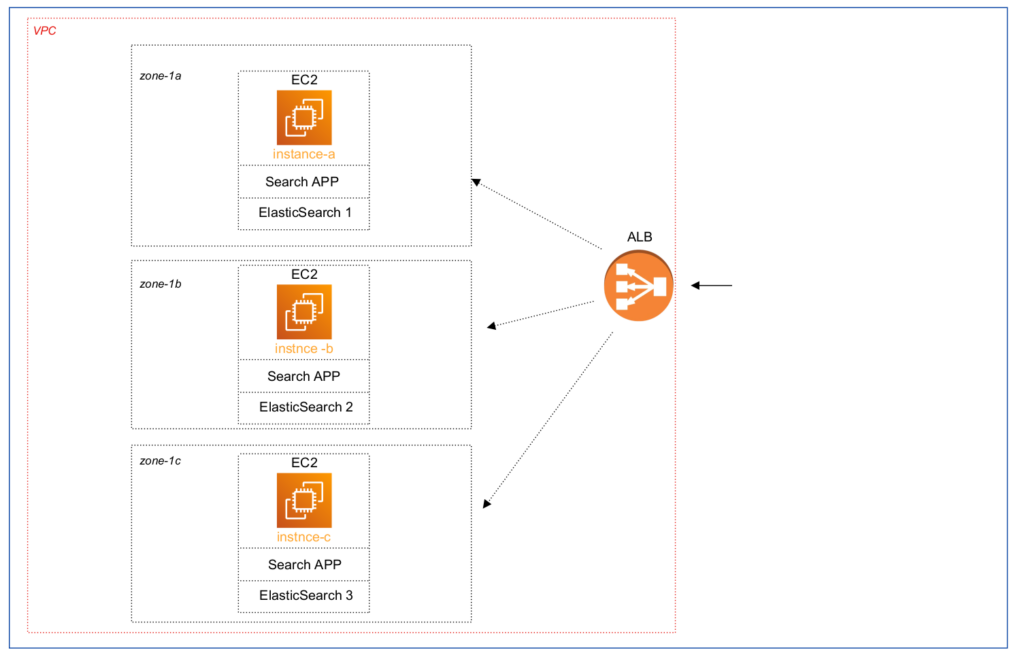
And the 1st step was successfully done. The next migration steps were as listed below:
- 2. Replace Elasticsearch cluster with AWS OpenSearch service
- 3. Move Search App from EC2 swarm cluster to the AWS Fargate
Our final goal was to get a scalable and serverless solution. Sounds reasonable, doesn’t it?
So, the 2d step was performed at the next iteration. As existing dockerized 3 node Elasticsearch cluster was limited at docker level to the 6GB RAM with JVM set to the 4GB, the solution was taken to use simplified 2 node OpenSearch cluster with m6g.large.search instance type (2 CPU, 8 GB RAM) to provide initial tests (yes, it was not HA, but at least less expensive). And in 2 weeks all was done – infrastructure with terraform, recreating index mappings, indexing tests, application unit and integration tests, and some other preparation – all problems were solved. So, we switched Search App at OpenSearch cluster.
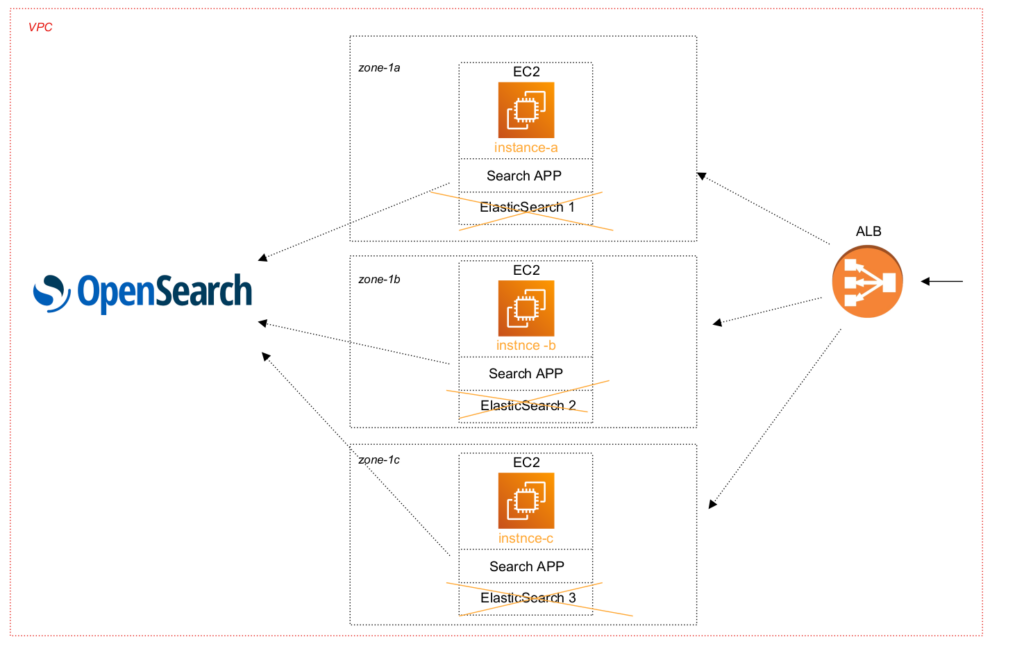
But our happiness didn’t last long. In several hours we had to switch back to the existing Elasticsearch cluster, which we preserved “just in case” 😉
So, what has happened? The deal is that we did not test one functionality. Here is a short description of how it works. Users can choose/set different options at their account for getting daily reports, including concrete hour. There is a cron at the beginning of every hour, which gathers users, whose report should be sent, and pushes according user’s ID at the SQS queue. Workers take user IDs from queues, create reports using data from Elasticsearch and send according info at user’s email. Here is simplified diagram for the whole process image:
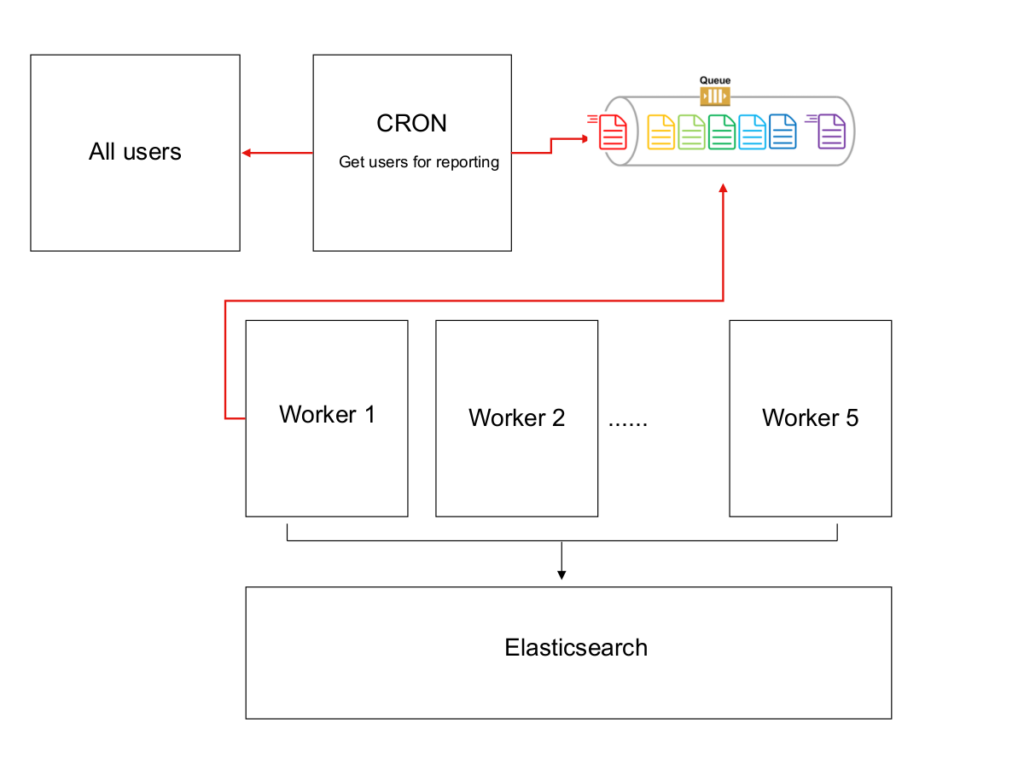
Some hours are much more popular than others. As a result, in peaks over then 10K users have to get reports. The search query by itself is rather complicated – it includes different advanced filters, including geolocation operations, and term’s aggregation based on filtered results. Moreover, as users’ settings are extremely different, the cardinality of search requests is very high – so cache is not helpful in the current case. That creates non typical overload peaks at Elasticsearch, but the existing cluster, despite increase in memory, CPU utilization and search latency, was able to deal with that without any bigger problems. But not OpenSearch. It appeared to be not resistant to the short peaks and refused to process queries with sending 429 errors – Too many requests. If you are interested in details – please visit my course ”AWS devops: Elasticsearch at AWS using terraform and ansible”. I will not reveal details here, the most essential is the final result – the decision “refuse from migration at OpenSearch” was taken. Yep, unfortunately.
But almost 2 years have passed, all infrastructure has been moved to AWS Cloud. The company, owner of Search App, grew up and became a serious player. As a result AWS appeared with questions about how they can help and what problems the company would like to resolve – question of OpenSearch migration was opened again. Here, I want to say “BIG THANK YOU” to the people (Robert, Julia, Francisco), who provided me useful instructions and AWS credits for perfoming additional tests. I will not put their surnames here, though I hope they recognize themselves during the reading of the current article. 🙂
So, my plan was the next. Deploy OpenSearch cluster using different instances type and:
- gather performance metrics using OpenSearch Benchmark utility
- imitate sending reports overload at Elasticsearch/OpenSearch clusters and test it’s behaviour
- compare AWS OpenSearch clusters with existing Elasticsearch EC2 3 node cluster – docker memory limit 6Gb, jvm – 4GB, t3.large (2 CPU, 8 GB)
- compare AWS OpenSearch clusters with scaled up Elasticsearch EC2 3 node cluster – docker memory limit 14Gb, jvm – 12GB, t3.xlarge (4 CPU, 16 GB)
OpenSearch Benchmark utility appeared to be easy to use. The most problematic was the part related with imitating real overloading while generating reports. I had to take 10K users (anonimize their all personal data but preserve their settings), modify cron code to ignore time preferences and modify workers code – to send search requests and generate reports without sending them to email. Finally, I indexed Elasticsearch with real production data and created an Elasticsearch snapshot from that at S3 to have the ability to dump it at different Opensearch clusters in a fast and convenient way.
Results appeared to be rather interesting. Let’s discuss it together in the next part, so if you are interested at current topic, please visit that page regularly or subscribe to my newsletter.
Below are the links to the courses, where you can find a lot of useful and, first of all, practical information about Elasticsearch: