Elasticsearch is document oriented, meaning that it stores entire objects or documents. It is not only stores them, but also indexes the contents of each document in order to make them searchable. In Elasticsearch, you index, search, sort, and filter documents—not rows of columnar data as we used to see it at relational databases. This is a fundamentally different way of thinking about data and is one of the reasons Elasticsearch can perform complex full-text search. Elasticsearch uses JSON format for documents. Here is the example of Elasticsearch document that has some hotel info:
{
"name":"Golden star hotel",
"stars":5,
"location":{
"lat":"52.229675",
"lon":"21.012230"
},
"info":{
"age":25,
"facilities":[
"parking",
"restaurant"
]
},
"created_at":"2014/05/01"
}So the first question that appears is: How to add such a document to Elasticsearch?
Before doing it we have to understand the Elasticsearch data architecture. Here is a slide that will help to understand it:
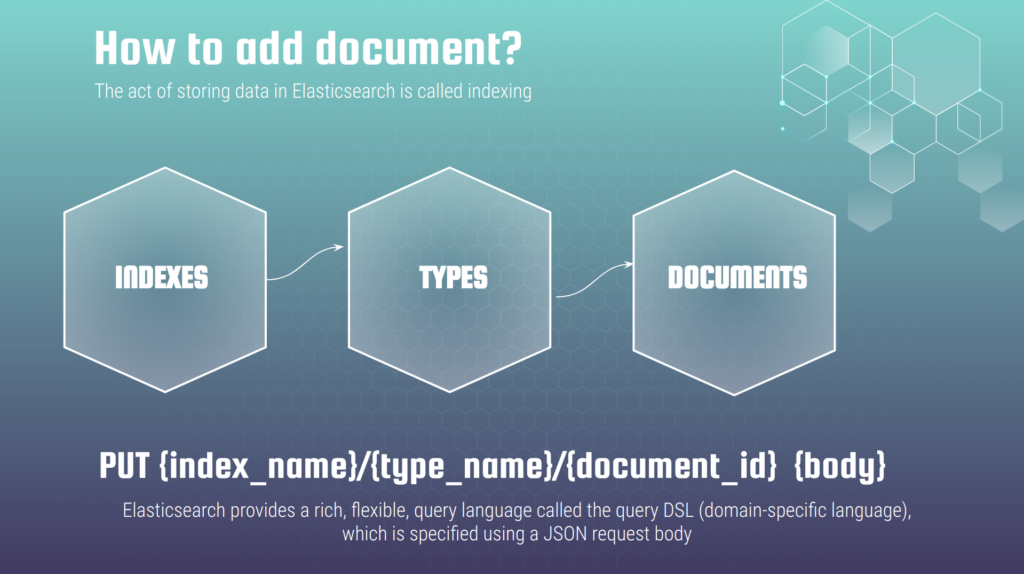
Elasticsearch organizes data at indexes. Every index can has multiple types. And every type can has multiple documents. From 6th version type is deprecated, from 8th version – it is removed at all. Though in fact it is still exist under the hood – simply it can be only one per index and it is created by default with service word “_doc” when index is created. So, now let’s return to adding the document at elasticsearch.
ElasticSearch expose REST API that allows us to perform different operation upon it. The general pattern for adding elasticsearch document, which is called indexing, is the next one:
PUT {index_name}/{type_name}/{document_id} {body}At first we specify HTTP word PUT, then index name, then type, and in the end – document id. Document id can me missed – in case it is absent elasticsearch will generate it automatically. From 6th version type should be _doc (as we have only one type that allowed per index which is created as default out of box and called _doc). The body have to be represented as a JSON object with using DSL – Domain Specific Language. From theory it sounds complicated. It is much more easier to understand it at real practice example. Lets assume that we already have running elasticsearch 7 instance at localhost:9200 and we want to add the document with hotel info mentioned above. We can use curl package for that purpose. It is easy to install it almost at any operation system. The console command for adding elasticsearch document using curl would be next (be careful with escaping new lines – it depends on your OS, look at explanations below) :
curl -XPUT localhost:9200/hotels/_doc/1 -d'
{
"name":"Golden star hotel",
"stars":5,
"location":{
"lat":"52.229675",
"lon":"21.012230"
},
"info":{
"age":25,
"facilities":[
"parking",
"restaurant"
]
},
"created_at":"2014/05/01"
}While running that query ElasticSearch will automatically create hotels index with _doc type and create document inside it with id=1 and json data, that we passed as a body. In similar way, using REST API we can get and delete the document we have just added:
curl -XGET localhost:9200/hotels/_doc/1
curl -XDELETE localhost:9200/hotels/_doc/1To replace an existing document with an updated version, we just PUT it again. I want to say several more words about update’s nature at Elasticsearch. Documents are immutable: they cannot be changed – only replaced. Update document process looks like: retrieve document, change it, and then reindex the whole document. There is partial update API, but in fact it makes the same – that is only decorator that performs the same update procedure under the hood.
For sure curl package is not the the best way to work with Elasticsearch. At first DSL queries are representing multi line JSON objects – depending on operational system it should be escaped, e.g at Linux we have to use backslashes. At second, and it is even more bigger problem, JSON structure is very sensitive – it is enough to miss some comma – and nothing would be working. Curl package will not help us to validate our json body. That is why it is better to use some special tools that can make our life easier. And now most people will say – no problem – we can use some programming language. Yes, we can, but to understand fundamentals better to stay at lower level. It will allow us to see raw queries and responses – that will allows to understand better what is going on with elasticsearch engine under the hood. And later, after understanding basics, it is worth to go further with programming languages (you may find examples of Elasticsearch integrations and different programming languages at my blogs -> go to the menu -> section “Tutorials”). So, at next article we will install elasticsearch head plugin and postman tool – that will allow us to work with elasticsearh in convenient way staying at lower level. We will also index several test documents and run first search queries upon it. Thank you for being with me whole that time. If you want to know more, please, wait for the next article or welcome to my course.