Hi, and welcome to the the series of articles where I will show you how to deploy an Elasticsearch cluster at AWS using ECS and terraform. At current lecture we will concentrate at ECS base components and architecture scheme. But before we start, let’s recall what is AWS ECS at all.
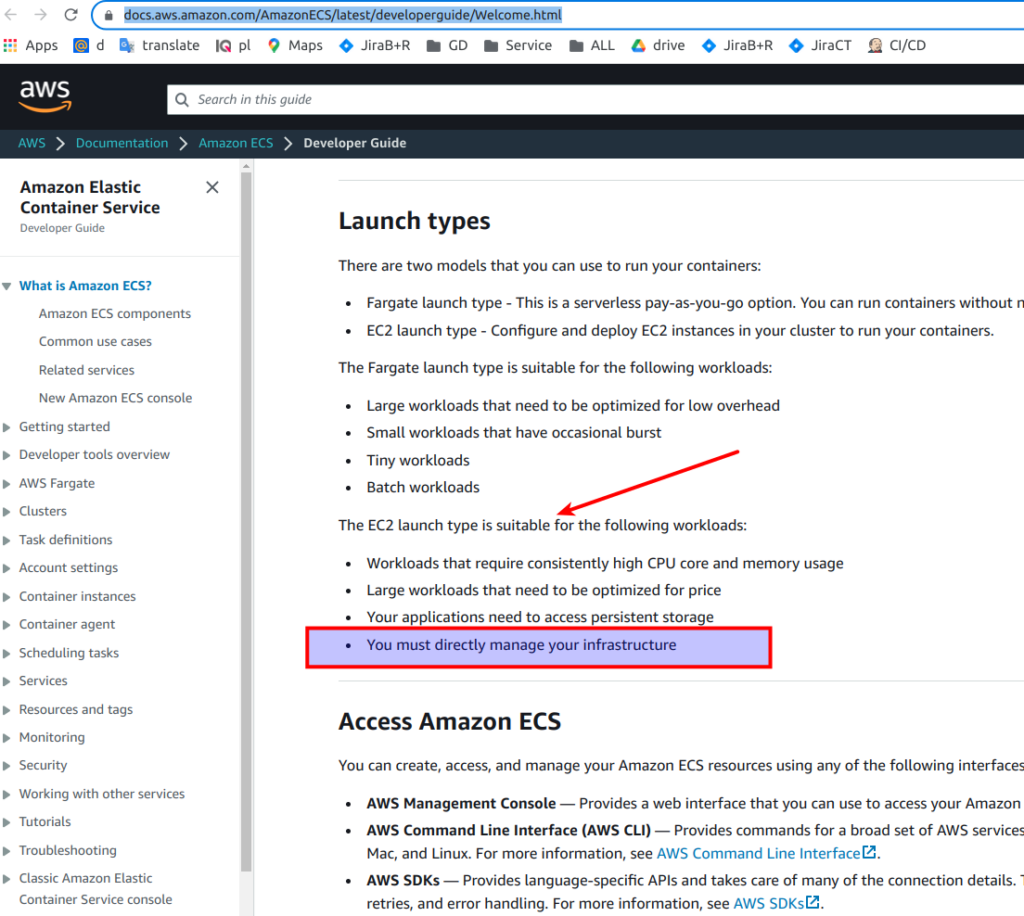
Amazon Elastic Container Service (ECS) – is a highly scalable and fast container management service. You can use it to run, stop, and manage containers on a cluster. So, in fact ECS is a docker orchestration tool. There are two models that you can use to run your containers: Fargate launch type and EC2 launch type. Let’s open AWS documentation for a while to decide what option is more suitable for us. From 1st glance it looks that Fargate is a better option. As for me if we can run containers and don’t manage infrastructure – then it is a preferable option. If something can be delegated to the cloud – then such an option simply has to be used. But there is a 1st pitfall here. And the problem lies at that line: “You must directly manage your infrastructure”
Why do we need – let’s open Elasticsearch official documentation. Pay attention to the current phrase – “The vm.max_map_count kernel setting must be”. Without that Elasticsearch will throw an exception like: “max virtual memory is too low”. I showed it in detail at my course “Elasticsearch as you have never known it before”.
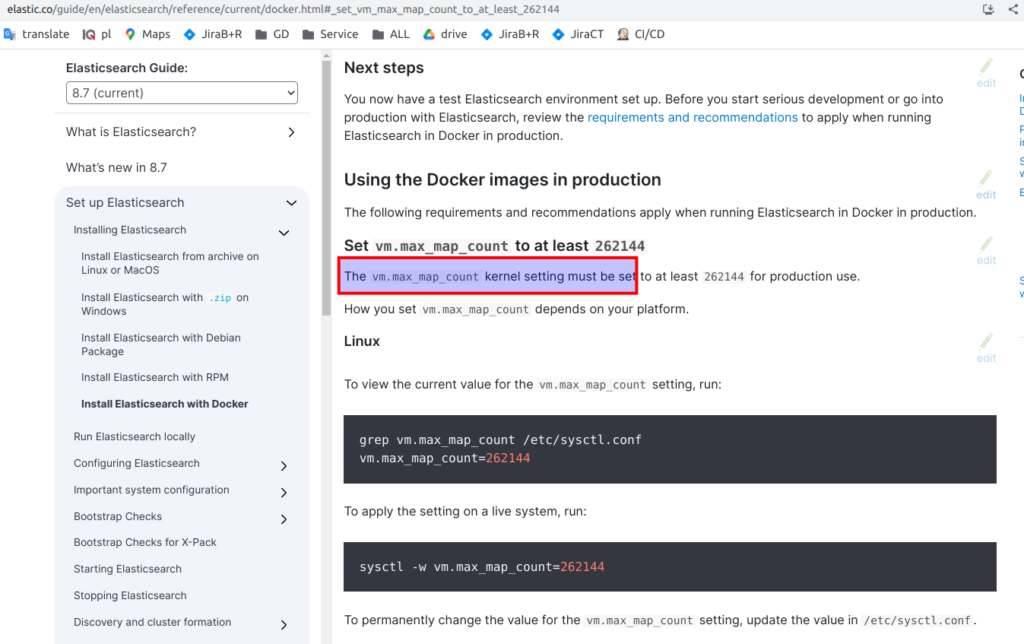
Here is the short explanation of vm.max_map_count problem:
- Docker actually wraps a process and runs it using the kernel installed on the host machine. Changing “vm.max_map_count” is actually configuring the Linux kernel of the host machine.
- When the host machine is under your control, such as when you use EC2, you can configure the kernel of the host machine by applying “user data” on your launch configuration.
- But where host machine is not under your control, as in the case of Fargate, you cannot change the host and the kernel settings it runs. The whole idea of Fargate is to run stateless Docker images, images that don’t make any assumptions on the host they run inside.
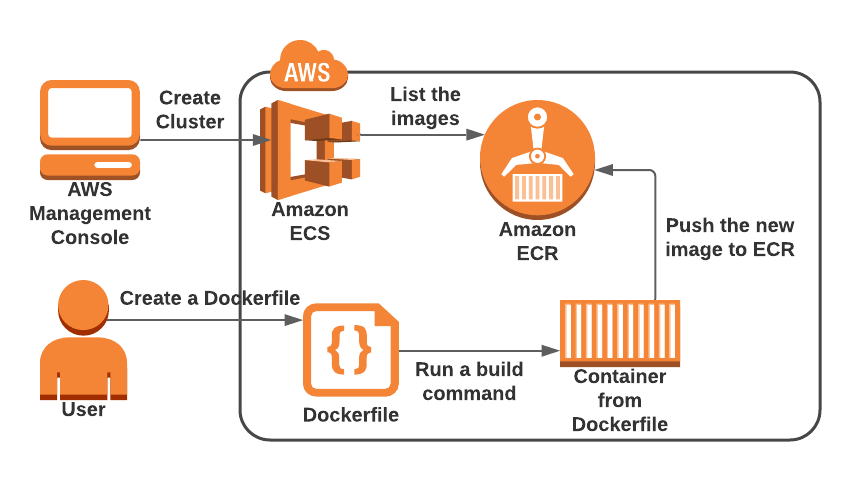
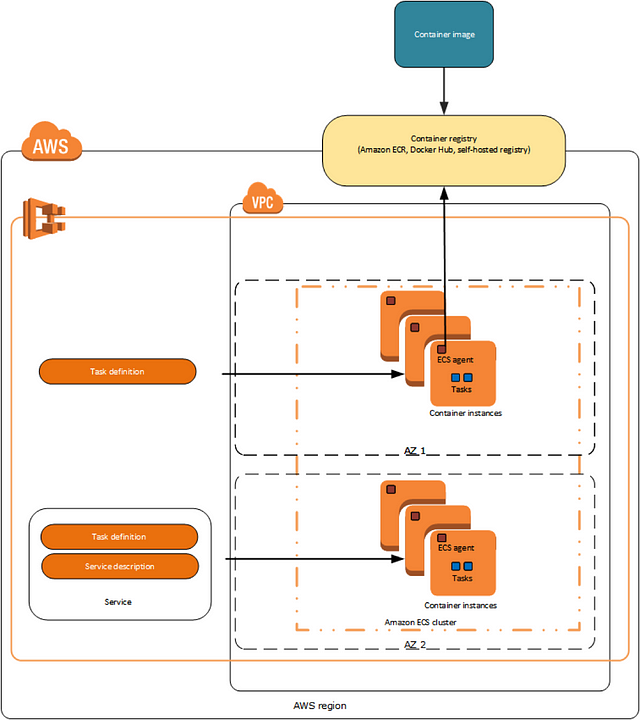
The summary is next – unfortunately we can’t use Fargate, the only possible solution for us is EC2 launch type. So, now when we deal with launch ECS type, let’s make the review of the whole steps we plan to perform from a higher architecture view. For readers who are not familiar with ECS basics I propose to to read next article from AWS ECS documentation. To deploy applications at ECS, the application by itself should be configured to run in a container. And that is what we will do also – we will create a Docker file for Elasticsearch, build an image and push it to the AWS container registry. Here small scheme that will help to understand the process:
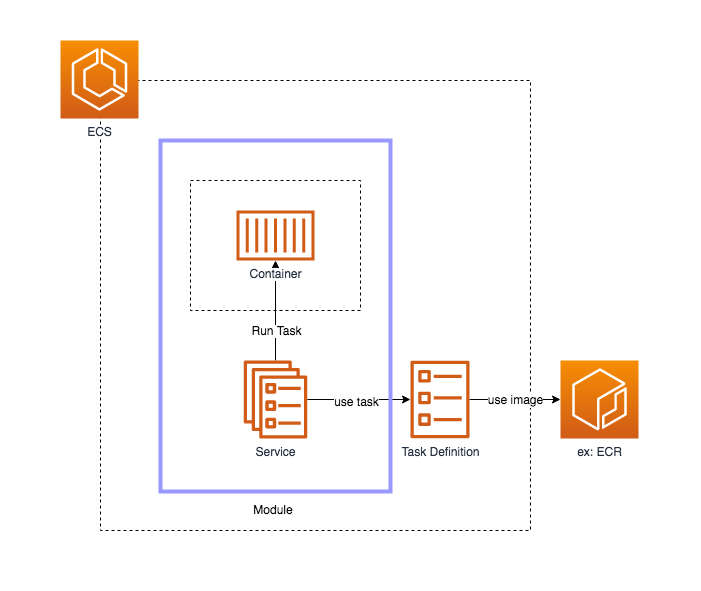
Then we have to define different parameters for our dockerized app and describe how exactly we want it to be run – that is done with using so-called task definition, which is nothing more than a json file with different properties. ECS uses task definition to run our dockerized app in the way we defined it. Such a “running” app is called a task. Then we have a next layer – it is called service – in fact it is a scheduler which helps us to maintain the desired number of tasks, we also can treat it as a task manager. Tasks and services are wrapped at the next logical abstraction layer which is called an ECS cluster.
As you understand, to run containers we need some real physical infrastructure. In case ECS can be EC2 and Fargate. Generally speaking Fargate – it is simply a higher abstraction layer for EC2, that is not something completely new – but only a good marketing step from AWS side. Anyway – we already found out that we can’t use Fargate to deploy an Elasticsearch cluster.
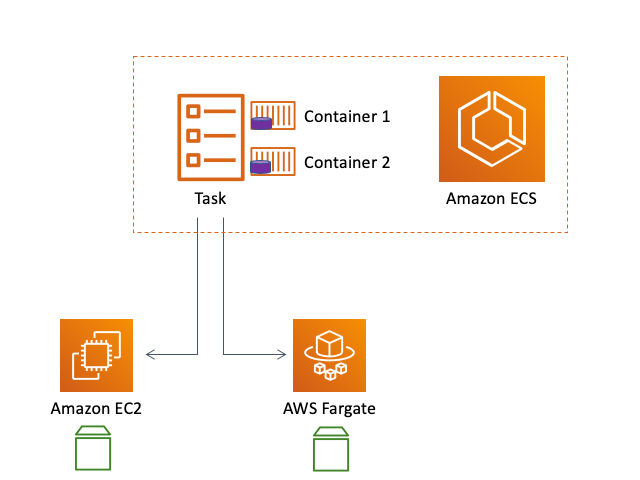
So, what is the EC2 launch type – that is EC2 instances with running special software which is called ECS agent. While deploying EC2 we have to declare a special custom data for every instance – that will allow ECS agent to register every EC2 instance to ECS cluster – in such a way the service will know where exactly he can run the tasks, and the rules which define how exactly every task should be run are described at tasks definition.
Now, when we know how ECS works let’s move to our case. We want to deploy a HA Elasticsearch cluster. As you remember we already have a network terraform module which creates for us the whole network structure. Hope that you still remember our network scheme:
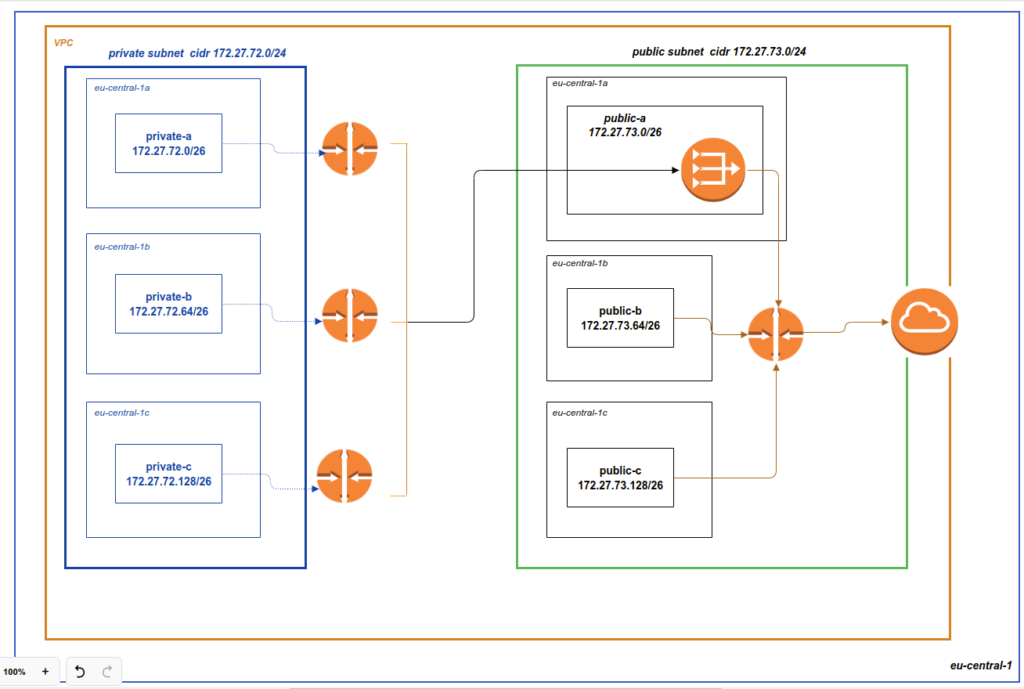
That is the 1st thing that we will have to recreate – but you already know how to do i, if not – please read about it at my blog. The next thing we are going to perform is to place EC2 instances with a pre-installed ECS agent at every private network. That would be done by a separate terraform module which we will create together. In such a way we will get the infrastructure for running our containers. And then we will finally define all stuff related to ECS by itself: task definition, service cluster and different permissions related to it. As always it would be realized by terrafrom.
Within the whole ES ECS deployment process, we will also use bastion extensively. That will allow us to connect to EC2 instances directly in order we could observe AWS magic under the hood. To deploy bastion we will use ready terraform module that was already represented at article: “Terraform bastion module“
So, great, now we are ready to create a Elasticsearch Docker file, build from it the image and push it to the AWS docker registry. Let’s do it in the next article.
New articles would be added gradually, so if you are interested at current topic, please visit that page regularly or subscribe to my newsletter. But if you are not ready to wait – then I propose you to view all that material at my on-line course at udemy. Below is the link to the course. As the reader of that blog you are also getting possibility to use coupon for the best possible low price.