Hi,
That is the beginning of article’s series devoted to the deep insides of Elasticsearch cluster. I will try to describe the most interesting and useful aspects of how Elasticsearch works, what is shards, what makes impact at performance, how to choose hardware and what parameters should be under constant monitoring. I will try to explain all as simple as possible sharing my 8 year’s commercial experience of using Elasticsearch as technology. At first part I will concentrate at Elasticsearch cluster conceptions. Let me put this to you simply – less text, more images:)
So, what is a cluster in Elasticsearch?
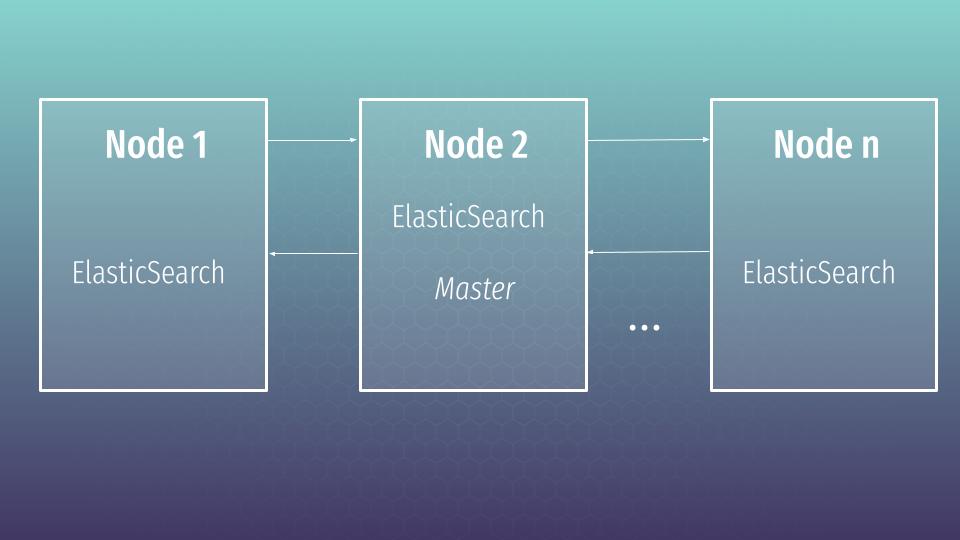
A node is a running instance of Elasticsearch, while a cluster consists of several nodes with the same cluster name, that are working together to share their data and workload. As nodes are added to or removed from the cluster, the cluster reorganizes itself to spread the data evenly.
At least one node in a cluster should perform a master role. Master manages cluster changes e.g add/remove indexes or add/remove nodes to the cluster. Master node does not need to be involved in search, though it can perform data operations at the same time. So why do we need the cluster in production?
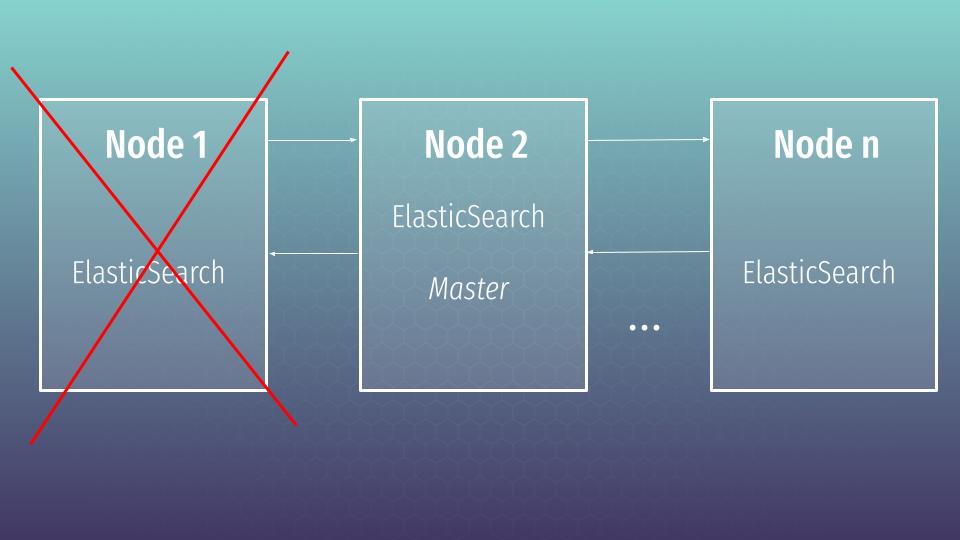
The answer is high availability (HA below in the text would be used as shortcut). Life is not perfect and any servers can be crashed or become unavailable at any time. Cluster will allow us to save our data and continue to work as nothing happens. Let’s try to understand how it works.
While creating index, Elasticsearch creates shards under the hood. Shard – that is logical and physical division of the index. Let’s imagine that we defined 3 shards. In that case Elasticsearch will spread shards as at current slide.
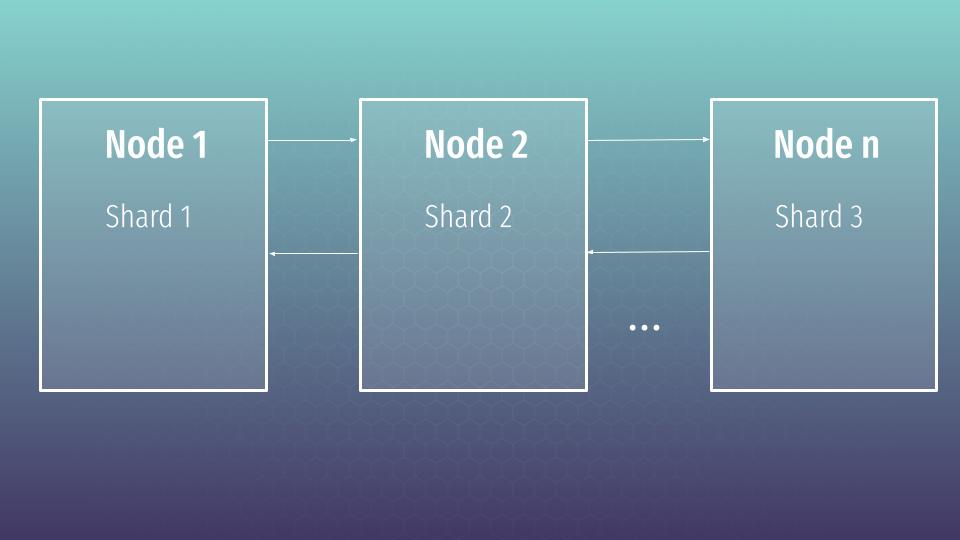
But shards can be primary or replica types. A replica shard is just a copy of a primary shard. Replicas are used to provide redundant copies of your data to protect against hardware failure, and to serve read requests like searching or retrieving a document.
So, let’s define the next settings for our index – 3 primary shards and 2 replicas for each primary one.
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 2
}
}In that case Elasticsearch will distribute shards in such a way to keep max redundancy. There are several possible scenarios how shards can be distributed. Let’s assume that we got next combination:
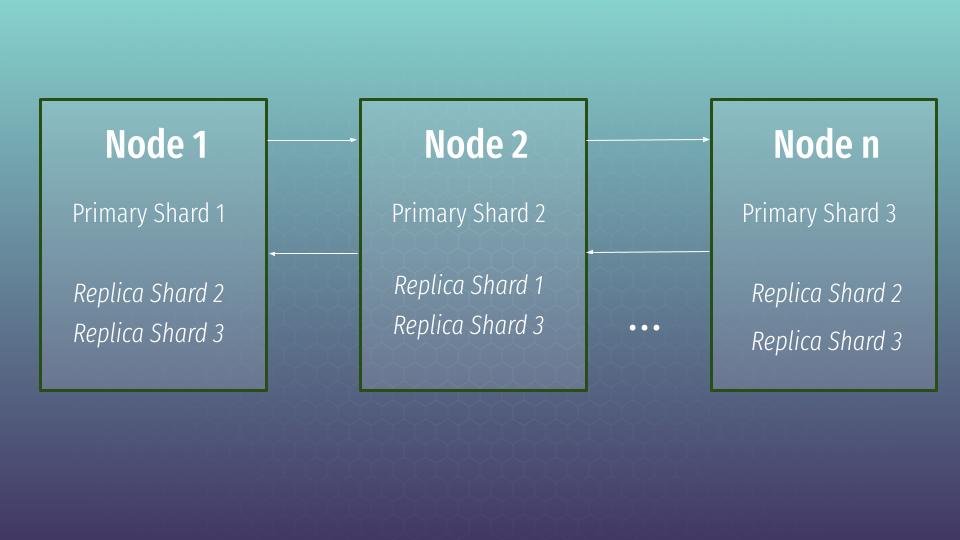
So, we have primary shard per node + plus replicas from missing primary shards. In that state our data is completely safe and that is called a green cluster state. Let’s imagine that one node has gone away. What will happen in that case?
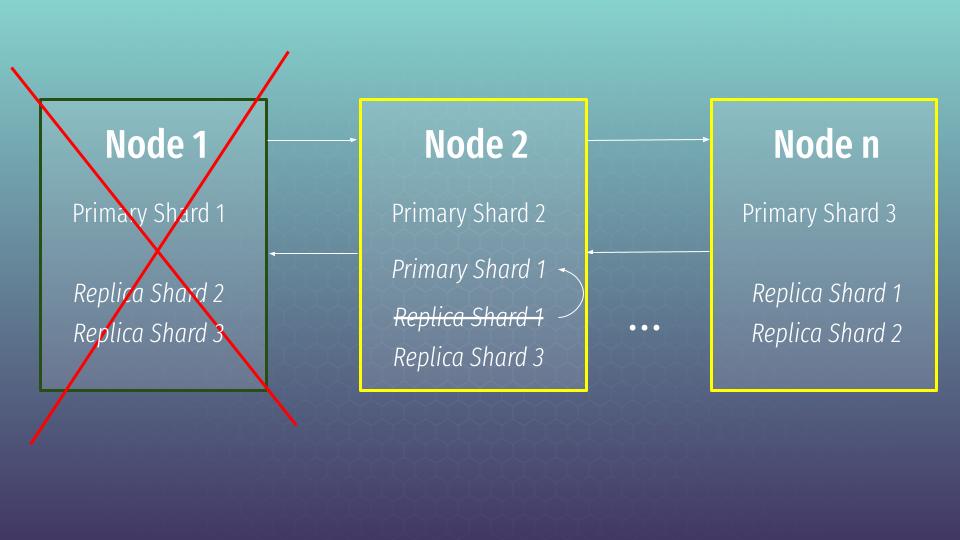
In that case master node will change replica shard 1 to primary one. But the cluster will switch to a yellow state, which means that all primary shards are active, but not all replica shards are active. In that case the cluster still continues to work and can process any request. There is also a red state, which means that not all primary shards are available. In that case the cluster will not be processing our requests at all.
Here I want to say several more words about the master. As you remember we need to have a master at cluster. Imagine, that the master appeared to be at node 1 – then a new master should be elected. And the process of election is not so trivial. First of all you can’t reach high availability having two nodes at a cluster because of a split brain problem. What it means?
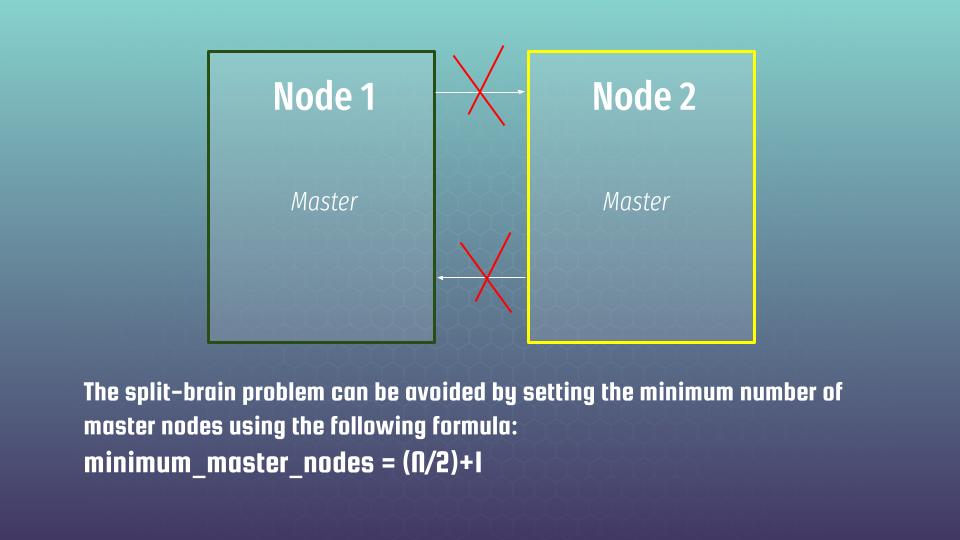
Imagine that you have two nodes and some 5 min network pause. Both nodes will decide that the other one is dead and both will take master roles. And imagine that within that time both nodes will perform some update of the same document at the same time. Then, network connection appears, but our data is not consistent any more – what should we chosen as the correct document state? There is no correct answer 🙁
What is the best practice to avoid the split-brain problem?
In case of 3 node cluster you have to configure all three nodes master-eligible – it means, that such cluster will be resilient to the loss of any single node. To elect a new master a majority is required. Such a majority is also called a quorum. So, in that case, two nodes can both confirm that 1st node has gone away in fact and that is not e.g some accidental temporary network pause. Then left nodes can decide who will become a master among them. Such a scheme allows to avoid split brain problems to the statistically super low probability. That all causes that to build a HA cluster – it is preferable to use an odd number of nodes e.g 3 or 5 but not even, like 4 or 6. You can read more about here and here.
So, choosing the correct number of primary and replica shards, and the number of nodes by itself, are essential things. But it is not essential only from HA side but also from performance aspect. Let’s speak about the performance and how to choose the right number of shards at the next article. Hope to see you soon.
P.S.
New articles would be added gradually, so if you are interested at current topic, please visit that page regularly or subscribe to my newsletter. But if you are not ready to wait – then I propose you to view all that material at my on-line courses at udemy. Below are the links to the courses, where you can find a lot of useful and, first of all, practical information about Elasticsearch: