Working with AWS logs often feels like drinking from a firehose.
WAF, ALB, CloudFront – they all happily generate hundreds of gigabytes of logs. The bigger your workloads grow, the more painful it becomes: queries run for ages, Athena bills keep climbing, and dashboards lag.
But here’s the thing: in 90% of cases, you don’t actually need all of the logs. You want a specific day, maybe a week, sometimes even just an hour. That’s where partitions come to the rescue.
Using Athena partitions and Parquet you can:
- Cut query runtime from minutes to seconds.
- Slash cost by scanning only the data you care about.
- Keep analytics flexible – day by day, hour by hour, or long-term aggregated.
In this post, I’ll walk you through practical ways of working with WAF, ALB, and CloudFront logs using partitions.
Why Partitions Matter
Athena charges per scanned TB. Run a “SELECT * FROM waf_logs” on a raw S3 bucket, and you’ll pay for every gigabyte. That might be fine once – but repeat this daily and costs snowball.
Partitions let you organize logs by year, month, day, hour – and query only the relevant slice. Think of it as cutting a huge watermelon into manageable pieces instead of trying to swallow it whole.
WAF Logs: Monthly and Daily Partitions
WAF logs tend to be heavy JSON objects. Instead of keeping one giant raw table, create partitioned tables.
Example:
CREATE EXTERNAL TABLE IF NOT EXISTS waf_logs (
timestamp BIGINT,
formatversion INT,
webaclid STRING,
terminatingruleid STRING,
terminatingruletype STRING,
action STRING,
terminatingrulematchdetails ARRAY<STRUCT<conditiontype:STRING, location:STRING, matcheddata:ARRAY<STRING>>>,
httpsourcename STRING,
httpsourceid STRING,
rulegrouplist ARRAY<STRUCT<
rulegroupid:STRING,
terminatingrule:STRUCT<ruleid:STRING, action:STRING, rulematchdetails:STRING>,
nonterminatingmatchingrules:ARRAY<STRUCT<
ruleid:STRING, action:STRING,
rulematchdetails:ARRAY<STRUCT<conditiontype:STRING, location:STRING, matcheddata:ARRAY<STRING>>>>
>,
excludedrules:ARRAY<STRUCT<ruleid:STRING, exclusiontype:STRING>>
>>,
ratebasedrulelist ARRAY<STRUCT<ratebasedruleid:STRING, limitkey:STRING, maxrateallowed:INT>>,
nonterminatingmatchingrules ARRAY<STRUCT<ruleid:STRING, action:STRING>>,
requestheadersinserted STRING,
responsecodesent STRING,
httprequest STRUCT<
clientip:STRING, country:STRING, headers:ARRAY<STRUCT<name:STRING, value:STRING>>,
uri:STRING, args:STRING, httpversion:STRING, httpmethod:STRING, requestid:STRING>,
labels ARRAY<STRUCT<name:STRING>>,
ja4fingerprint STRING
)
PARTITIONED BY (year int, month int, day int, hour int)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://ct-prod-waf-logs/'
TBLPROPERTIES (
'projection.enabled' = 'true',
'projection.year.type' = 'enum',
'projection.year.values'='2024,2025,2026',
'projection.month.type' = 'enum',
'projection.month.values'='01,02,03,04,05,06,07,08,09,10,11,12',
'projection.day.type' = 'enum',
'projection.day.values'='01,02,03,04,05,06,07,08,09,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31',
'storage.location.template'='s3://your_s3_bucket_name_for_waf_logs/${year}/${month}/${day}/${hour}/'
);ALB Logs: Regex-Based Tables
ALB logs use a different structure – plain text with regex parsing. Same idea though: partition by date, and query smaller chunks.
CREATE EXTERNAL TABLE IF NOT EXISTS alb_logs (
type string,
time string,
elb string,
client_ip string,
client_port int,
target_ip string,
target_port int,
request_processing_time double,
target_processing_time double,
response_processing_time double,
elb_status_code int,
target_status_code string,
received_bytes bigint,
sent_bytes bigint,
request_verb string,
request_url string,
request_proto string,
user_agent string,
ssl_cipher string,
ssl_protocol string,
target_group_arn string,
trace_id string,
domain_name string,
chosen_cert_arn string,
matched_rule_priority string,
request_creation_time string,
actions_executed string,
redirect_url string,
lambda_error_reason string,
target_port_list string,
target_status_code_list string,
classification string,
classification_reason string,
conn_trace_id string
)
PARTITIONED BY (
year int,
month int,
day int
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1',
'input.regex' = '([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) (.*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-_]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^ ]*)\" \"([^\s]+?)\" \"([^\s]+)\" \"([^ ]*)\" \"([^ ]*)\" ?([^ ]*)?( .*)?'
)
LOCATION 's3://ct-prod-lb-logs/prod/AWSLogs/289613372540/elasticloadbalancing/eu-central-1/'
TBLPROPERTIES (
'projection.enabled' = 'true',
'projection.year.type' = 'enum',
'projection.year.values'='2024,2025,2026',
'projection.month.type' = 'enum',
'projection.month.values'='01,02,03,04,05,06,07,08,09,10,11,12',
'projection.day.type' = 'enum',
'projection.day.values'='01,02,03,04,05,06,07,08,09,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31',
'storage.location.template' = 's3://tour_bucket_name_for_alb_logs/AWSLogs/289613372540/elasticloadbalancing/eu-central-1/${year}/${month}/${day}/'
);
The structure/scheme of logs sometimes is changed by AWS – in that case queries should be changed. In case errors – look at last documentation:
- Create a table for AWS WAF S3 logs in Athena using partition projection
- Create the table for ALB access logs in Athena using partition projection
CloudFront Logs: Parquet for the Win
CloudFront is a bit trickier: logs are written in a flat structure, no built-in partitions. That means raw queries can be painfully expensive.
Generally you have several options here.
At first, you may convert logs to such a structure the partitions can be used. For that purpose you will have to use some lambda attached to CloudFront or Amazon Kinesis for log’s streaming. But, it is connected with additional costs. I will not discover that possibilities here, though that solution has it’s own advantage – you are getting “real-time” data for querying. But it is not always required.
There is second option. The trick? Convert CloudFront logs into Parquet tables.
For a single day/hour:
CREATE TABLE cf_tmp_logs_2025_08_18_08_09
WITH (
format = 'PARQUET',
parquet_compression = 'SNAPPY',
external_location = 's3://your_s3_bucket_name_for_keeping_parquet_data/scratch/2025-08-18-08-09/',
partitioned_by = ARRAY['hour']
) AS
SELECT
date, time, location, bytes, request_ip, method, host, uri, status, referrer,
user_agent, query_string, cookie, result_type, request_id, host_header,
request_protocol, request_bytes, time_taken, xforwarded_for,
ssl_protocol, ssl_cipher, response_result_type, http_version,
fle_status, fle_encrypted_fields, c_port, time_to_first_byte,
x_edge_detailed_result_type, sc_content_type, sc_content_len,
sc_range_start, sc_range_end,
-- partitions
CAST(substr(CAST(date AS varchar), 1, 4) AS INT) AS year,
substr(CAST(date AS varchar), 6, 2) AS month,
substr(CAST(date AS varchar), 9, 2) AS day,
substr(time, 1, 2) AS hour
FROM cloudfront_logs
WHERE date = DATE '2025-08-18'
AND CAST(substr(time, 1, 2) AS integer) BETWEEN 8 AND 9;
Where cloudfront_logs is a table for raw flatten CloudFront real-time logs.
Unfortunately, it is not possible to run it for bigger periods of time (e.g the whole month or even week – it depends how many GB of logs you are generating daily) as you will get error like that one:
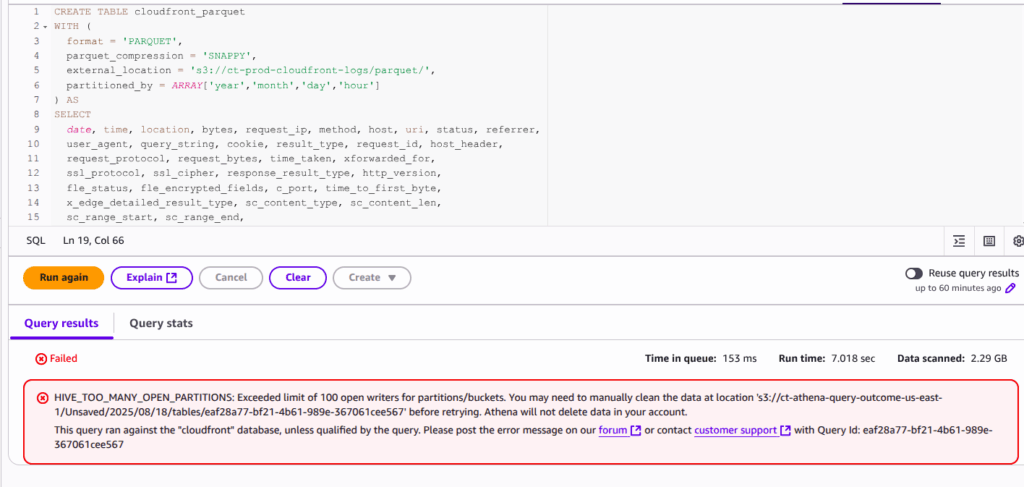
Though you can create a bigger dataset appending days/hours one by one. Here is an example how to add data from the next hour to existing table:
INSERT INTO cf_tmp_logs_2025_08_18_08_09
SELECT
date, time, location, bytes, request_ip, method, host, uri, status, referrer,
user_agent, query_string, cookie, result_type, request_id, host_header,
request_protocol, request_bytes, time_taken, xforwarded_for,
ssl_protocol, ssl_cipher, response_result_type, http_version,
fle_status, fle_encrypted_fields, c_port, time_to_first_byte,
x_edge_detailed_result_type, sc_content_type, sc_content_len,
sc_range_start, sc_range_end,
-- partitions (same projection as in CTAS)
CAST(substr(CAST(date AS varchar), 1, 4) AS INT) AS year,
substr(CAST(date AS varchar), 6, 2) AS month,
substr(CAST(date AS varchar), 9, 2) AS day,
substr(time, 1, 2) AS hour
FROM cloudfront_logs
WHERE date = DATE '2025-08-18'
AND substr(time, 1, 2) = '9';Remember – insert operations will not automatically add new records. Unfortunately, Athena INSERT INTO does not do “incremental merge”. It will simply append all rows that match your WHERE clause, every time you run it. So if you run:
- At 09:30 today rage: BETWEEN ‘8’ AND ’10’; → it will insert all rows so far today (08:00–09:30).
- At 09:45 → BETWEEN ‘8’ AND ’10’; it will insert all rows so far today again (08:00–09:45), which duplicates everything from 08:00–09:30.
With a plain Parquet table, Athena can’t “insert and overwrite” a partition. So, to refresh hour=09:
- Delete the S3 prefix: s3://your_s3_bucket_name_for_keeping_parquet_data/scratch//2025-08-18-08-09/hour=09/
- Insert data for the whole 9th hour
This is safe but requires manual delete of that hour’s prefix each time. Alternative option here can be using Apache Iceberg table type
CREATE TABLE cloudfront_iceberg
WITH (
table_type = 'ICEBERG',
format = 'PARQUET',
location = 's3://your_s3_bucket_name_for_keeping_parquet_data/parquet_iceberg/',
partitioning = ARRAY['year','month','day','hour']
) AS
SELECT ... same SELECT as your CTAS for 2025-08-17 ...;
-- append by hour
INSERT INTO cloudfront_iceberg
SELECT ... WHERE date=current_date AND substr(time,1,2)=date_format(current_time,'%H');
-- if you ever need to rebuild a day (no S3 deletes)
INSERT OVERWRITE cloudfront_iceberg
SELECT ...
WHERE date = DATE '2025-08-18';Iceberg gives you INSERT OVERWRITE and snapshots—great for shared teams.
In case Parquet – use year, month, day, hour and only then narrow time filter, look at screen to compare performance between almost the same queries upon the same parquet table within the same time range:
Wrong approach – no partitions are used:
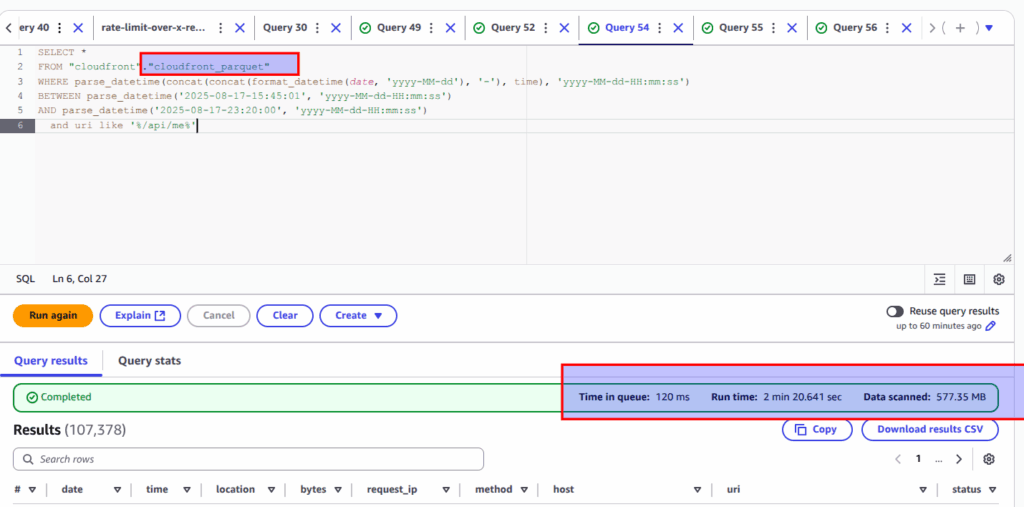
Correct approach:
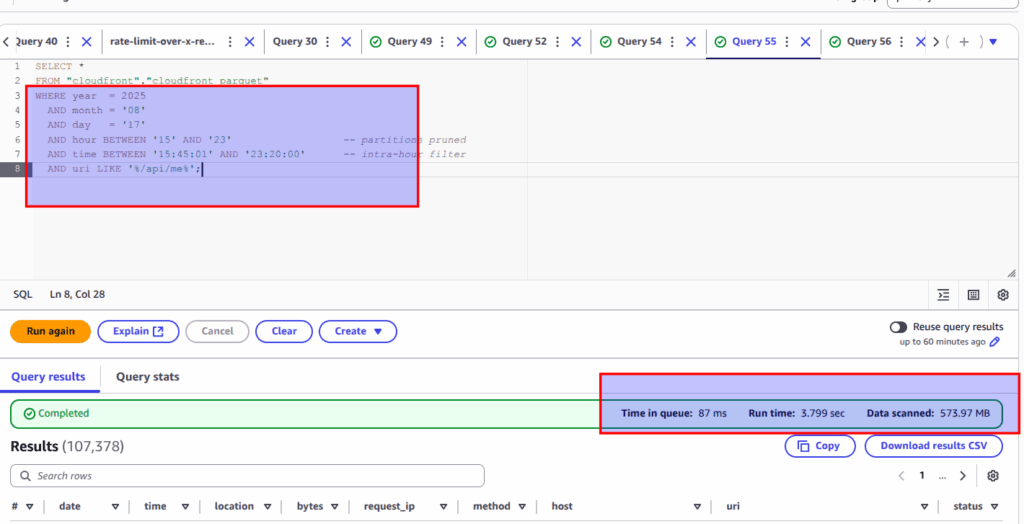
Impressive, does not it?
In addition, let me provide the same query upon raw real time logs 🙂
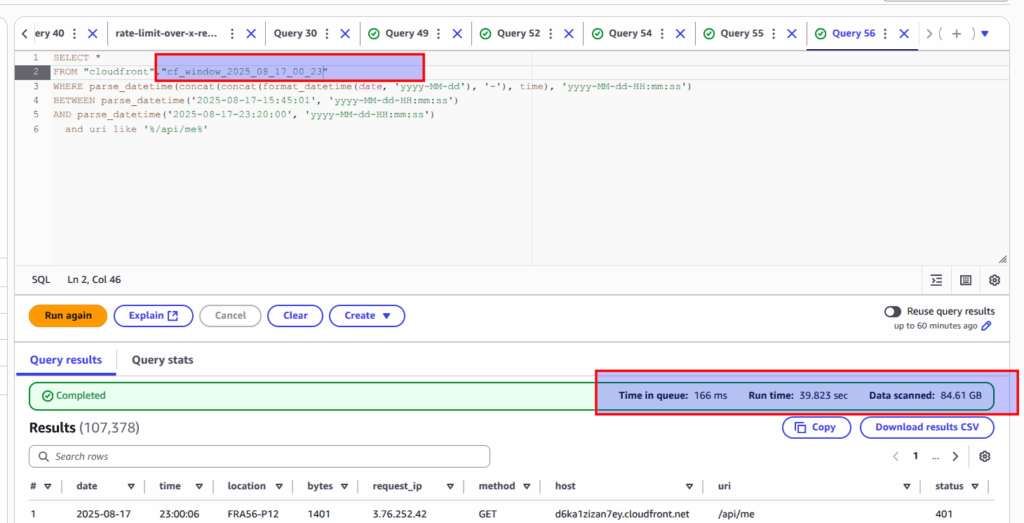
As you see, within running query upon raw flat data, Athena scanned almost 85 GB of data vs 0.5 GB, but even that appeared to be faster when you are using parquet in a wrong way. Here is the explanation why it happens:
- Using timestamp with
parse_datetime(concat(...))prevents full partition pruning. Athena still pruned some (hence 577 MB), but it listed lots of partitions and opened many tiny files. - CTAS (Create Table As Select) often writes multiple small Parquet files per partition. Opening many small files adds overhead even if bytes scanned are low.
- Athena must write the full result set to your results S3. Writing 100k rows can be tens of seconds regardless of scan size.
Summary: Build you query wise – and you will get fast and cheap results – e.g 0.5 GB of data is scanned at 4 sec at our “correct” example.
In case parquet, I would like to give also one more recommendation:
Avoid SELECT *. Only project what you actually use in the analysis/report. This alone often halves runtime. Parquet is fastest when you read only the columns you need.
Automation: Daily CloudFront Parquet
Manually creating tables is fine for experiments. But for ongoing analytics, better to automate it.
For that purpose I am using small scheduled Lambda at 01:30 AM that converts yesterday’s raw CloudFront logs into Parquet + partitions and stores them in parquet table at S3, where retention is set to 60 days.
That way, monthly or weekly analytics run smoothly without manual cleanup. I will show ready terraform solution for that at the next article, which will appear soon. If you do not want to miss it, sign up to my newsletter:
Pro Tips
- Partition wisely – year/month/day/hour is a good balance.
- Know when raw logs are enough – sometimes for a quick one-day query, raw logs may be faster.
- Avoid
SELECT *– only project the fields you need. Cuts runtime in half. - Always watch AWS docs – AWS occasionally tweaks log schemas. If queries break, check the latest docs.
Final Thoughts
Partitioning logs in Athena is one of those “small effort – big win” tricks. Your queries become faster, your bills lighter, and your patience saved.
Whether it’s WAF, ALB, or CloudFront, the principle is the same: don’t query the ocean when you only need a glass of water.
Best regards!