
Hi,
Recently I’ve met a problem with REDIS memory usage at AWS ElastiCache service. It appeared that after some release, that happened 2 weeks ago, memory usage started to grow gradually like a snail. As result our memory monitoring caught the problem rather late. Here is the screen for AWS CloudWatch how it looked.
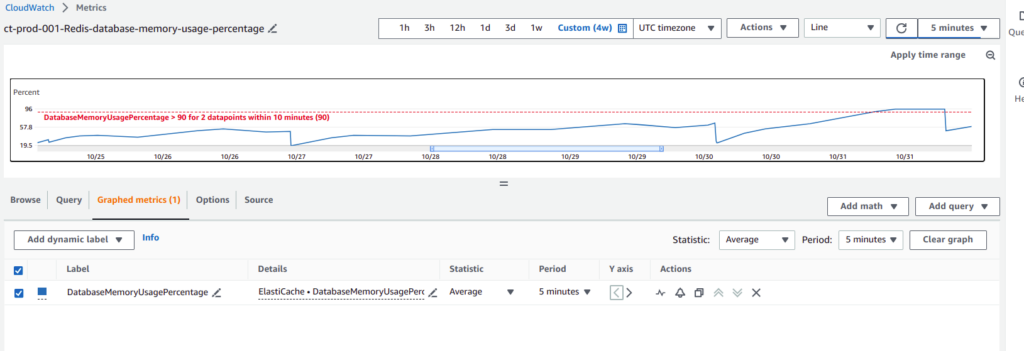
While analyzing release by itself, I found a lot of changes related with caching – so it was really hard to localize the problem from the code side by itself. Moreover, rolling back changes from 2 weeks also did not look to be a good a idea. After thinking a little bit, I decided to diagnose the problem of memory consuming at Redis directly. And it appeared to be a small adventure. Hope that my experience and solutions, which are provided below, will safe somebodies time. 🙂
First of all, I was not in a hurry, as I was sure our cluster will not fall down. You may ask:

The answer lies in the the Redis configuration and how is it used. In case you are using Redis or AWS ElastiCache for caching, which is probably the most typical kind implementation, it is always good to configure Redis cache invalidation at allkeys-lru type. The deal is by default, memory policy is set to the volatile-lru type, which means, that Redis will remove key only when it’s expiration would happen. But in that case, it is easy to get at situation, when your Redis cluster or instance will appear to be full – and “BOOMS” – you will get an memory exception. For some applications it can be really critical. If you are using Redis for caching – then you may not take care about data a lot and use more aggressive allkeys-lru policy, It will remove keys gradually accordingly to the LRU algorithm , which means (in simplified version) – “remove least recently used or the most old data”. So, if you have never heard about it – here is the 1st trick you can use at Redis config file:
maxmemory-policy allkeys-lruNow, let’s return to the problem by itself. My main goal was to localize keys, that gradually took Redis memory. It is good practice to preserve some namespaces and prefixes at Redis – and we are keeping that strategy. Hope that you are also preserving that approach, or at least you have some naming conventions/rules for generating Redis keys. If not – that is the 2nd recommendation – DO IT. For example, it is common practice to use such a pattern for creating key names:
group_prefix_name : namespace_name : unigue_key_nameWhat I had to do, is to group all keys by their namespaces/prefixes and find out which group takes too much space. Sounds easy – but not at practice. After looking at internet for any ready solutions, I finally found one repository. Big “THANK YOU” for it’s owner. He did a really great cli tool. First of all it is written in “Go” programming language, as result we have high performance. At second, after reading the initial code, I found it to be written really good:
- it uses non blocking SCAN command, which is very important at production;
- it is able to scan via subset of keys to optimize the process;
- and last, but the most essential thing – grouping number of keys to get their number is not so difficult, but it does not reflect the size in Mb. Redis does not provide any good option to measure the size of key’s value. The author of the tool used DUMP method, which serialize the value stored at key in a Redis-specific format and return it to the user. The length of received result from dump command does not reflect the real size in Mb, but it still allows to identify the “hot” place. Though even here all is not so easy. Redis dump command is rather slow, so providing measurement calculations at all key’s dataset would not be effective. But in fact – there is no need to do it. The author of that amazing tool applied smart tricky approach – he takes only small random validation subset to get rough estimation. Let me show how to use current tool in practice:
- Clone repository
- Install “Go” programming language – at linux you can do it using e.g: apt install golang-go
- Run: go build -o redis-usage
And now several examples how to use current tool. Let’s assume, that key names at REDIS are preserving best practices and looks like as:
.....
cache:api:order_21345
cache:app:main_page_45463
session:app:79a140737893aba49f023f56a382a510
....Let’s assume also, that we want to check how many size in Mb our keys with “cache” prefix take relatively to “session” prefix. It is enough to run 2 commands:
./redis-usage -host {your_host_here} -port {your_port_here} -limit 10000 -dump-limit 100 -prefixes cache
./redis-usage -host {your_host_here} -port {your_port_here} -limit 10000 -dump-limit 100 -prefixes sessionAfter running the commands you will see nice classical progress bar and size statistics.

Be attentive with parameters:
- limit – limit the number of keys scanned
- dump-limit – Use DUMP to get key sizes (much slower). If this is zero then DUMP will not be used, otherwise it will take N sizes for each prefix to calculate an average bytes for that key prefix. If you want to measure the sizes for all keys set this to a very large number.
For me it worked really good even while using rather big values both for limit and dunp-limit parameters – but still better to start from some small values, and then increase parameters gradually. You may use match option or several prefixes at once, separating them by comma. So, that was “tip and trick” number three 🙂
The last one useful command, that I would like to share with you, is how to remove “garbage” keys from Redis at production at safe, effective and the most simple way. Here is according command:
redis-cli -h {your_host_here} -p {your_port_here} --scan --pattern '*api*' | xargs redis-cli -h -h {your_host_here} -p {your_port_here} unlinkCurrent command will perform removing data from Redis in non-blocking way. It can be used also in case you need to free memory while extinguishing the fire or at deployment process to clear cache for some concrete namespace.
Hope, that you will find current article to be useful. Thank you for your attention. P.S. You may also subscribe to my newsletter to be aware of new articles. Best regards.